

fiddler的操作非常简单,即开即用型,这里简单备注一下吧。
一、打开浏览器
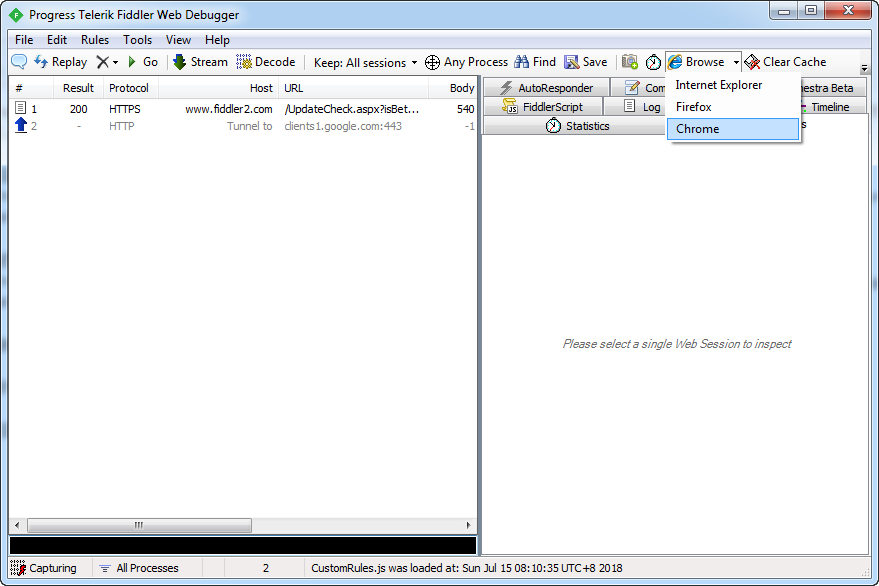
二、清空原始数据
点击图标上的那个“X”,然后执行“remove all”功能。
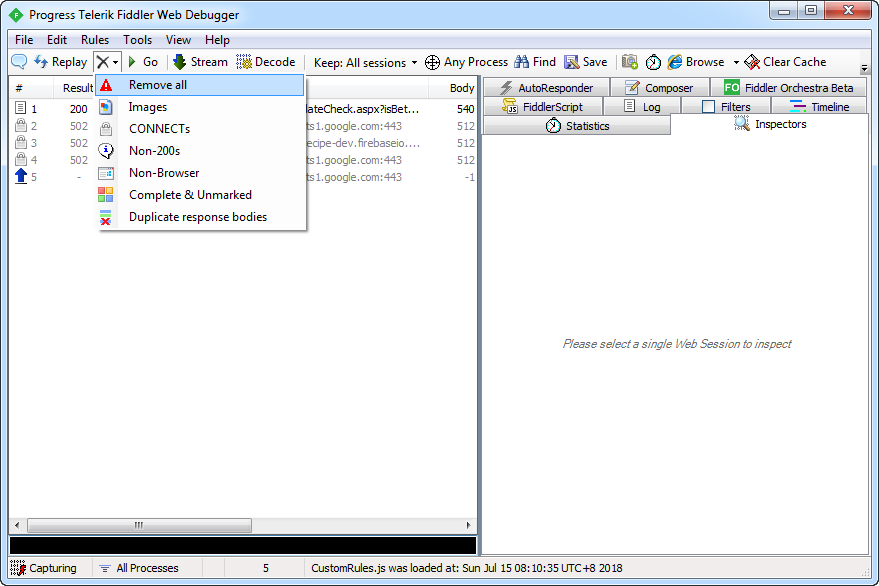
三、访问网站
在刚刚打开的浏览器中输入网址,回车。
点击左边的任意一条记录,在右边窗格就会显示相关的信息。
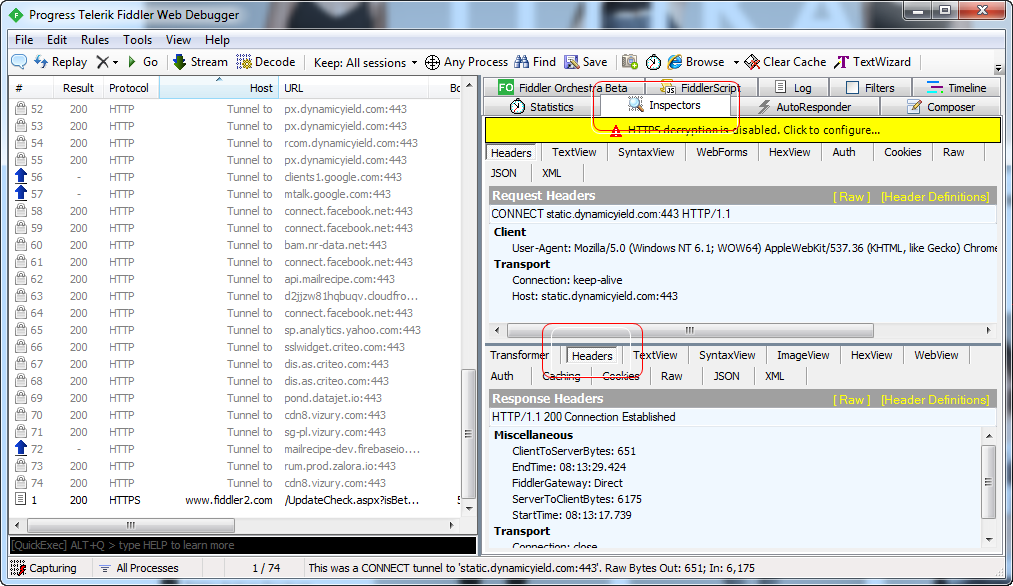
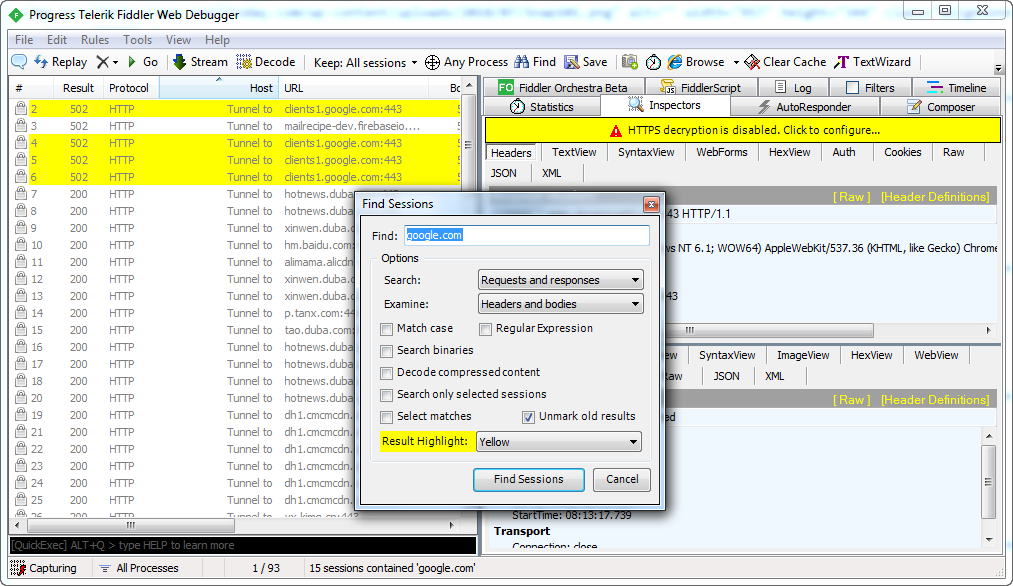
四、查找数据
点击工具栏上的“find”按钮,可以设定查询条件,查询到的结果会以黄色显示。
今天在用scrapy测试爬取一个网站的时候,老是不成功。我在chrome的xpath插件里可以取到数据,但是进入scrapy shell里面看,又没有取到数据。
后来通过浏览器右键查看源码,发现它的html代码是这样的:
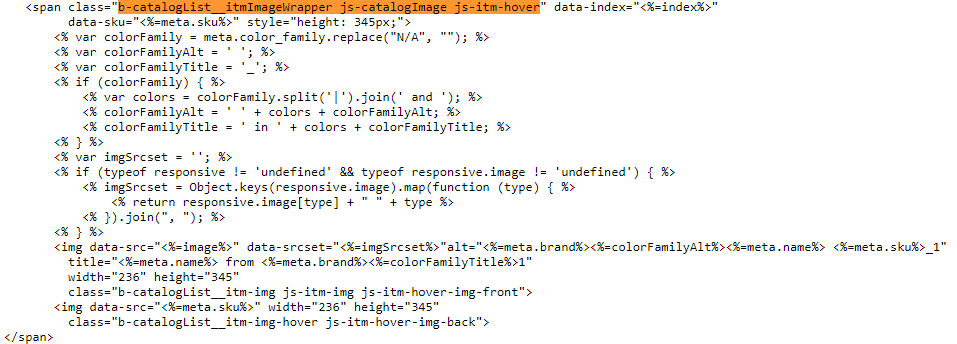
然后它的数据是以json格式渲染的。
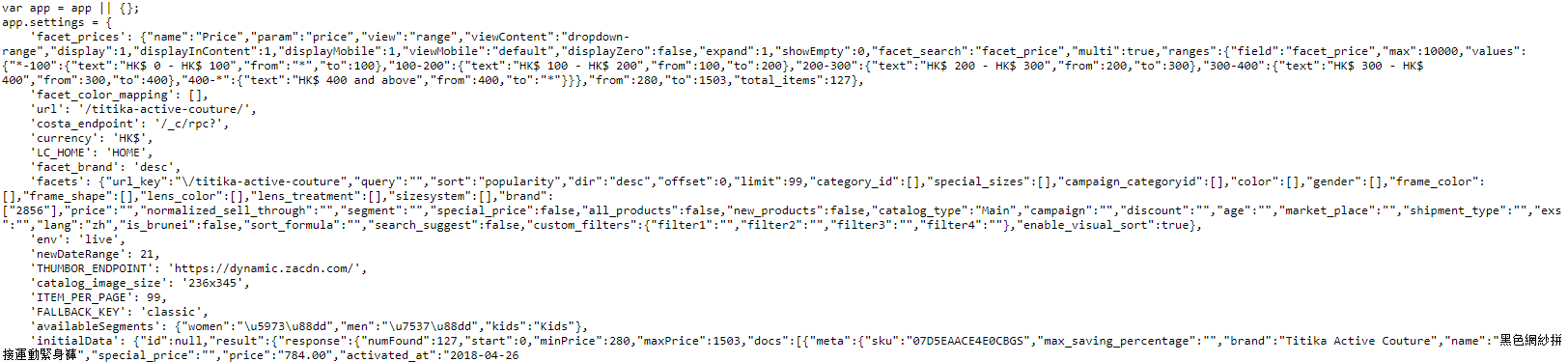
用F12没有找到这个api的接口,然后又改用fiddler,所以才有了这篇文章。
不过我用fiddler还是没有找到这个接口,最终通过一个一个查看js文件,最后在api_dynamic.js这个文件才找到的。
https://github.com/aldwyn/zalora-scraper/blob/master/zalorascraper/spiders/zaloraspider.py