

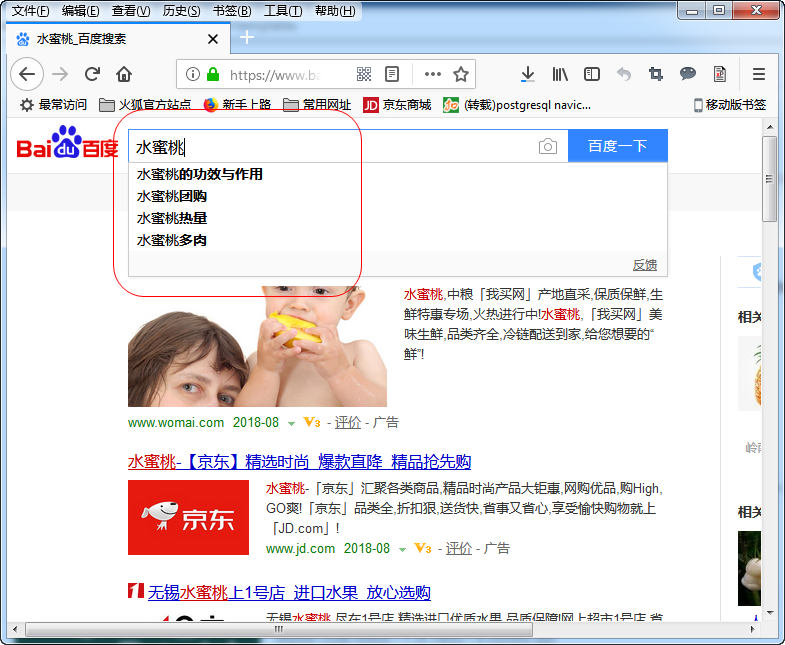
一、首先看看我们要采集的是百度搜索时,自动推荐功能显示的关键词。
代码如下:
import requests
import json
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=%s&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2&pbs=%%E5%%BF%%AB%%E6%%89%%8B&csor=2&pwd=%%E5%%BF%%AB%%E6%%89%%8B&cb=jQuery11020924966752020363_1498055470768&_=1498055470781' % word
r = requests.get(url)
content = r.text.replace('jQuery11020924966752020363_1498055470768(', '')
content = content.replace(');', '')
res_json = json.loads(content)
return (res_json['s'])
"""
把a~z遍历一遍,会出现更多关键词
"""
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i)
return list(set(all_words)) # 去重
"""
再次遍历,获得更多关键词
"""
def get_most_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
for j in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i+j)
return list(set(all_words)) # 去重
# print('\n'.join(get_more_sug('黄山')))
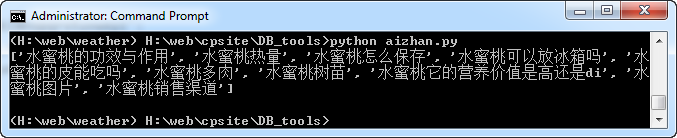
print(get_sug('水蜜桃'))
效果图如下:
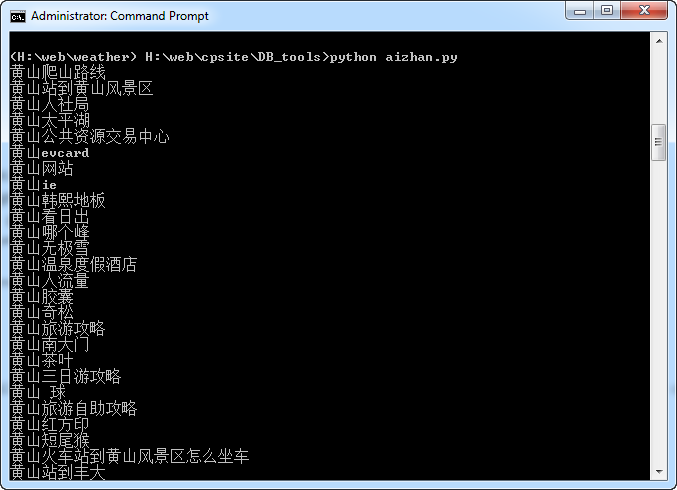
加入换行符之后的效果:
Updated on Oct-18-2020
二、采集百度搜索底部的相关关键词
1.安装必要的库
pip install fake-useragent
不过发现运行时有时会报错:
Error occurred during loading data. Trying to use cache server https://fake-user
agent.herokuapp.com/browsers/0.1.11
所以如果不需要的话可以注释掉。
2.相关代码
import requests,time,random
from lxml import etree
from fake_useragent import UserAgent
def get_keyword(keyword):
data=[]
ua=UserAgent()
headers={
'Cookie': 'PSTM=1558408522; BIDUPSID=BFDF2424811E5E531D933DC854B78C67; BAIDUID=BFDF2424811E5E531D933DC854B78C67:SL=0:NR=10:FG=1; MSA_WH=375_812; BD_UPN=12314353; H_WISE_SIDS=144367_142699_144157_142019_144883_141875_141744_143161_144989_144420_144134_142919_144483_136861_131246_137745_144743_138883_140259_141942_127969_144171_140065_144338_140593_143057_141808_140350_144608_144727_143923_131423_144289_142206_144220_144501_107312_143949_144105_144306_143478_144966_142911_140312_143549_143647_144239_142113_143855_136751_140842_110085; BDUSS_BFESS=1vQzN4d0pPNzB2MUQyUUQtV3d6OEZzYldhN2FWUm1RZEZ3UUVyb1Y1Mmtqc0JlSVFBQUFBJCQAAAAAAAAAAAEAAACgwJmS08W4xcTuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKQBmV6kAZleVW; MCITY=-%3A; sug=3; sugstore=0; ORIGIN=0; bdime=0; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=LuuOJexroG3_dMRrBfK9UG9zgmKK0gOTDYLEUamaI2AU2V4VN4vPEG0Pt_U-mEt-J8jwogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tbkD_C-MfIvhDRTvhCcjh-FSMgTBKI62aKDs2P5aBhcqJ-ovQTbrbMuwK45hB5cP3b5E0b6cWKJJ8UbeWfvp3t_D-tuH3lLHQJnp2DbKLp5nhMJmBp_VhfL3qtCOaJby523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-tt6De3j; delPer=0; BD_CK_SAM=1; PSINO=7; H_PS_PSSID=1457_31670_32141_32139_32046_32230_32092_32298_26350_32261; COOKIE_SESSION=7_0_4_5_9_5_0_3_2_3_0_0_1608_0_0_0_1594720087_0_1594723266%7C9%23328033_18_1594447339%7C9; H_PS_645EC=8046hkQMotVPI51%2B5I0oGWsgl5ams9mPpS71Aw1L%2FgLPGzpf4I2A6FpO8U4',
#'User-Agent': random.choice(ua_list)
'User-Agent': ua.random,
}
url=f"https://www.baidu.com/s?wd={keyword}&ie=UTF-8"
html=requests.get(url,headers = headers,timeout=5).content.decode('utf-8')
time.sleep(2)
try:
req=etree.HTML(html)
tt=req.xpath('//div[@id="rs"]//text()')
tt.remove('相关搜索')
print(tt)
data=tt
except Exception as e:
print(e.args)
time.sleep(5)
print(f">> 等待5s,正在尝试重新采集 {keyword} 相关关键词")
get_ua_keyword(keyword)
return data
def get_ua_keyword(keyword):
data = []
print(f'>> 正在采集 {keyword} 相关关键词..')
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
]
headers = {
'Cookie': 'PSTM=1558408522; BIDUPSID=BFDF2424811E5E531D933DC854B78C67; BAIDUID=BFDF2424811E5E531D933DC854B78C67:SL=0:NR=10:FG=1; MSA_WH=375_812; BD_UPN=12314353; H_WISE_SIDS=144367_142699_144157_142019_144883_141875_141744_143161_144989_144420_144134_142919_144483_136861_131246_137745_144743_138883_140259_141942_127969_144171_140065_144338_140593_143057_141808_140350_144608_144727_143923_131423_144289_142206_144220_144501_107312_143949_144105_144306_143478_144966_142911_140312_143549_143647_144239_142113_143855_136751_140842_110085; BDUSS_BFESS=1vQzN4d0pPNzB2MUQyUUQtV3d6OEZzYldhN2FWUm1RZEZ3UUVyb1Y1Mmtqc0JlSVFBQUFBJCQAAAAAAAAAAAEAAACgwJmS08W4xcTuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKQBmV6kAZleVW; MCITY=-%3A; sug=3; sugstore=0; ORIGIN=0; bdime=0; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=LuuOJexroG3_dMRrBfK9UG9zgmKK0gOTDYLEUamaI2AU2V4VN4vPEG0Pt_U-mEt-J8jwogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tbkD_C-MfIvhDRTvhCcjh-FSMgTBKI62aKDs2P5aBhcqJ-ovQTbrbMuwK45hB5cP3b5E0b6cWKJJ8UbeWfvp3t_D-tuH3lLHQJnp2DbKLp5nhMJmBp_VhfL3qtCOaJby523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-tt6De3j; delPer=0; BD_CK_SAM=1; PSINO=7; H_PS_PSSID=1457_31670_32141_32139_32046_32230_32092_32298_26350_32261; COOKIE_SESSION=7_0_4_5_9_5_0_3_2_3_0_0_1608_0_0_0_1594720087_0_1594723266%7C9%23328033_18_1594447339%7C9; H_PS_645EC=8046hkQMotVPI51%2B5I0oGWsgl5ams9mPpS71Aw1L%2FgLPGzpf4I2A6FpO8U4',
'User-Agent': random.choice(ua_list)
}
url = f"https://www.baidu.com/s?wd={keyword}&ie=UTF-8"
html = requests.get(url, headers=headers, timeout=5).content.decode('utf-8')
time.sleep(2)
try:
if '相关搜索' in html:
req = etree.HTML(html)
tt = req.xpath('//div[@id="rs"]//text()')
tt.remove('相关搜索')
print(tt)
data = tt
else:
print(f">> {keyword} 无相关关键词!! ")
data=[]
except Exception as e:
print(e.args)
print(f">> 采集 {keyword} 相关关键词失败!! ")
print('>> 正在保存失败关键词..')
with open('fail_keywords.txt', 'a+', encoding='utf-8') as f:
f.write(f'{keyword}\n')
return data
def lead_keywords():
print('>> 正在导入关键词列表..')
try:
with open('keyss.txt','r',encoding='gbk') as f:
keywords=f.readlines()
except:
with open('keyss.txt','r',encoding='utf-8') as f:
keywords=f.readlines()
print(keywords)
print('>> 正在导入关键词列表成功!')
return keywords
def save(datas):
print('>> 正在保存相关关键词列表..')
with open('keywords.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(datas))
print('>> 正在保存相关关键词列表成功!')
def main():
datas=[]
keywords=lead_keywords()
for keyword in keywords:
keyword.strip()
data=get_keyword(keyword)
datas.extend(data)
save(datas)
if __name__ == '__main__':
main()