

机器学习可以主要分为几类:监督学习,非监督学习,增强学习及推荐系统等。
一、第三课 Pandas
1.代码1
import pandas as pd
def test_run():
start _date='2010-01-01'
end_date = '2011-01-26'
dates = pd.date_range(start_date,end_date)
df1 = pd.DateFrame(index=dates)
dfspy = pd.read_csv("data/spy.csv",index_col = "Date",parse_dates = True, usecols=['Date','Adj Close'],na_values=['nan'])
df1=df1.join(dfspy)
df1 = df1.dropna()
print(df1)
2.how='inner'的用法
直接向join的how传入参数,{{left, right, outer, inner},default为left,outer为取并集,inner为交集,left是保留左边dataframe的index,right是右边的index
这样就不用像上面一样还要删掉nan了
df1.join(dfspy,how='inner')
3.subset
def get_data(symbols, dates):
"""Read stock data (adjusted close) for given symbols from CSV files."""
df = pd.DataFrame(index=dates)
if 'SPY' not in symbols: # add SPY for reference, if absent
symbols.insert(0, 'SPY')
for symbol in symbols:
# TODO: Read and join data for each symbol
df1 = pd.read_csv(symbol_to_path(symbol),index_col = "Date",parse_dates = True, usecols=['Date','Adj Close'],na_values=['nan'])
df1 = df1.rename(columns ={'Adj Close':symbol})
df = df.join(df1)
if symbol == 'SPY':
df = df.dropna(subset=["SPY"])
return df

总结:
df取数据的三种方法:
第一种 取行
第二种 取列
第三种 取行+列

第二部分
1.什么时候有效果

2.Normalization

三、第三部分
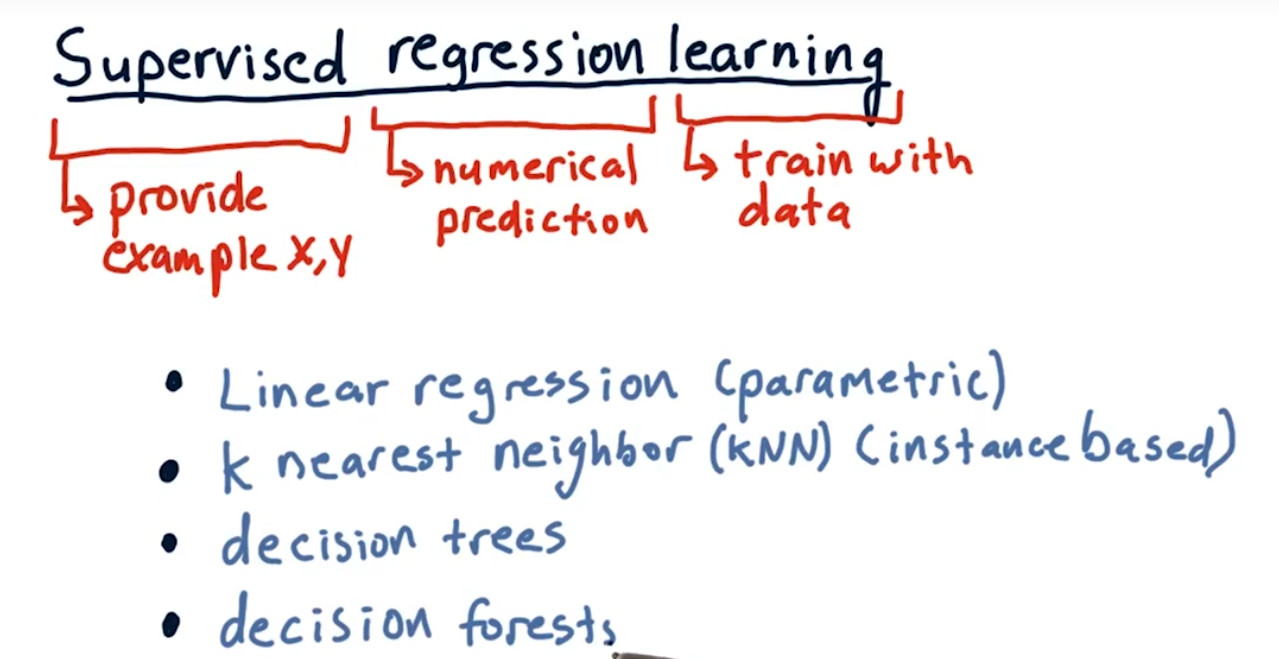
1.supervised regression learning的四种方法
(1)Linear Regression:因为是获得参数,所以又叫parametric learning

(2)KNN:又叫Instance Based Learning。与linear regression不同的地方是,预测时会使用源数据。它不包含训练函数这个过程,只需要把所有数据放在数据库里,投入新的数据时,只需要去数据库里查找。(如果给每个y不同的权重,这就成了Kernel Regression)
K的值有何影响?
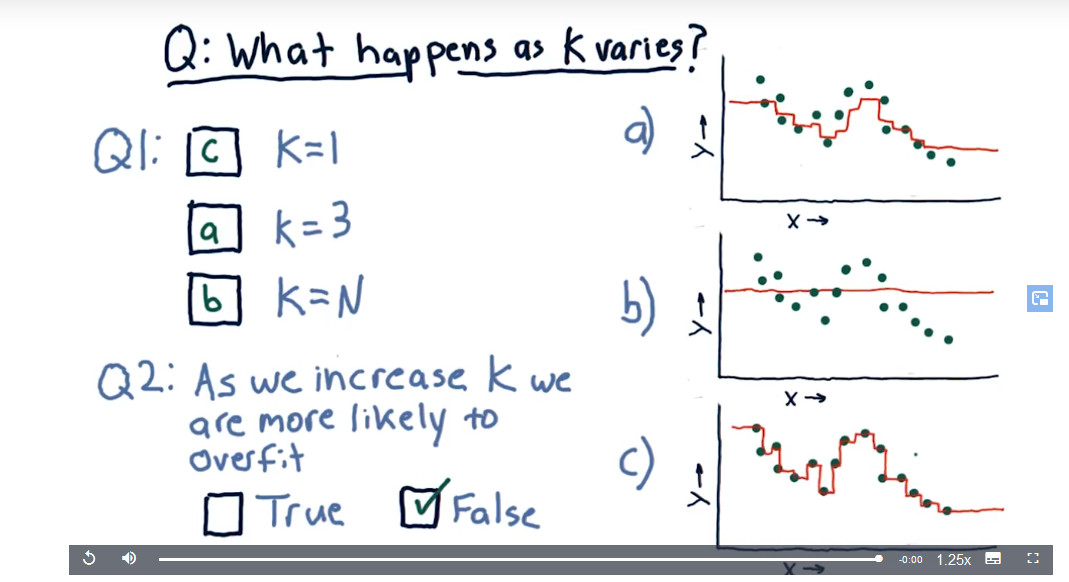
(3)decision trees:
(4)decision forests:多个决策树组成。
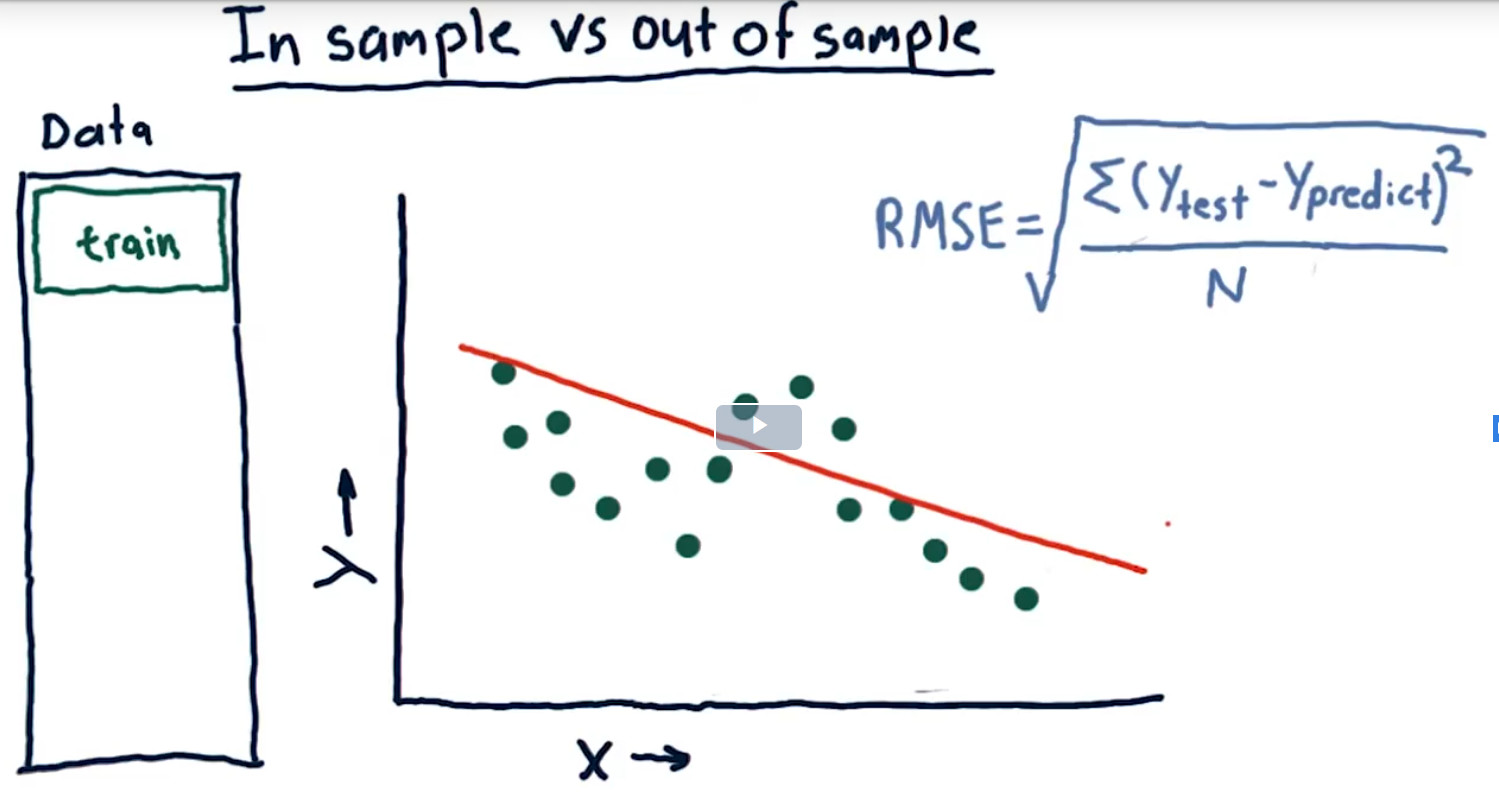
2.RMSE
MSE(Root Mean Squard Error)均方根误差。
参考:回归评价指标MSE、RMSE、MAE、R-Squared https://www.jianshu.com/p/9ee85fdad150
3.预测结果与实际值的对比
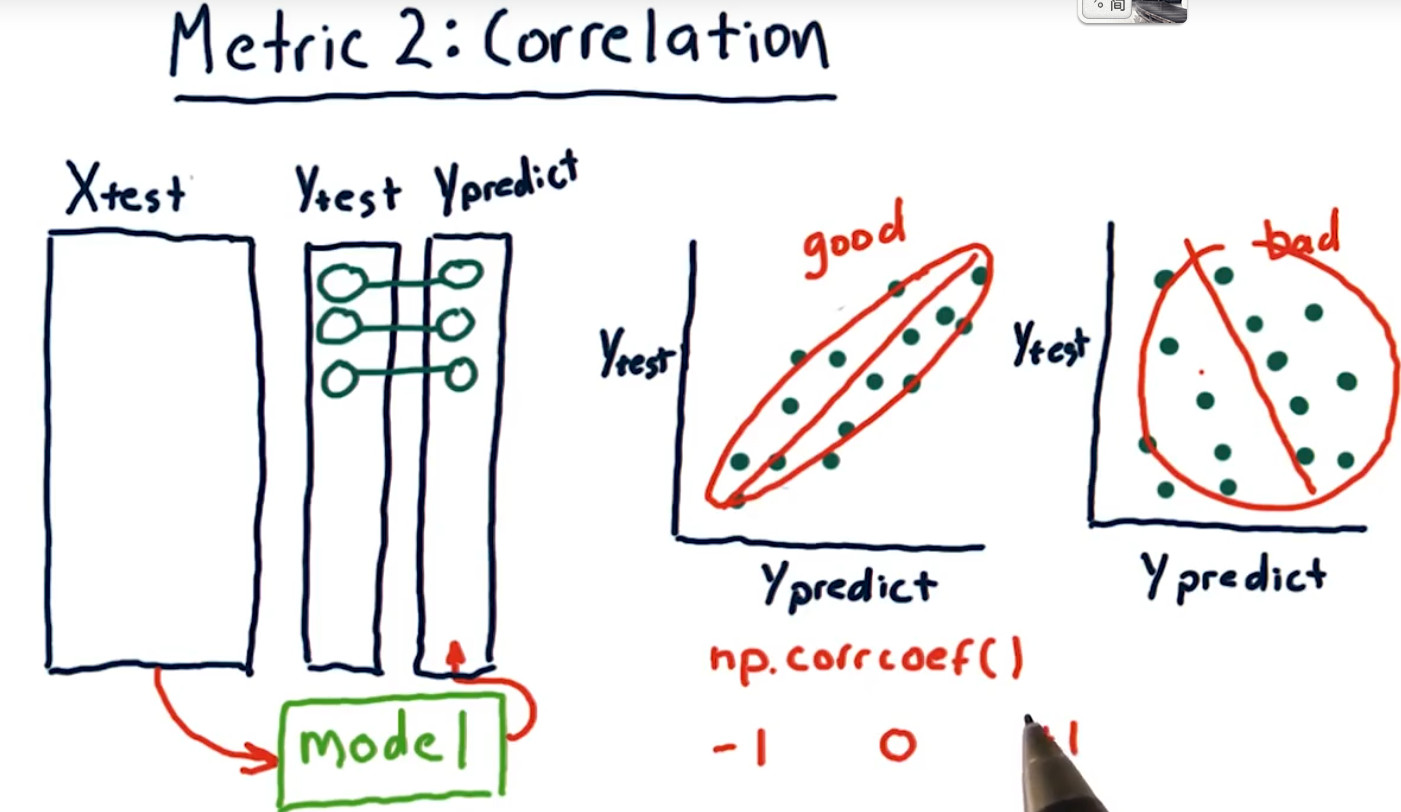
当RMSE变大,相关性correlation变小。

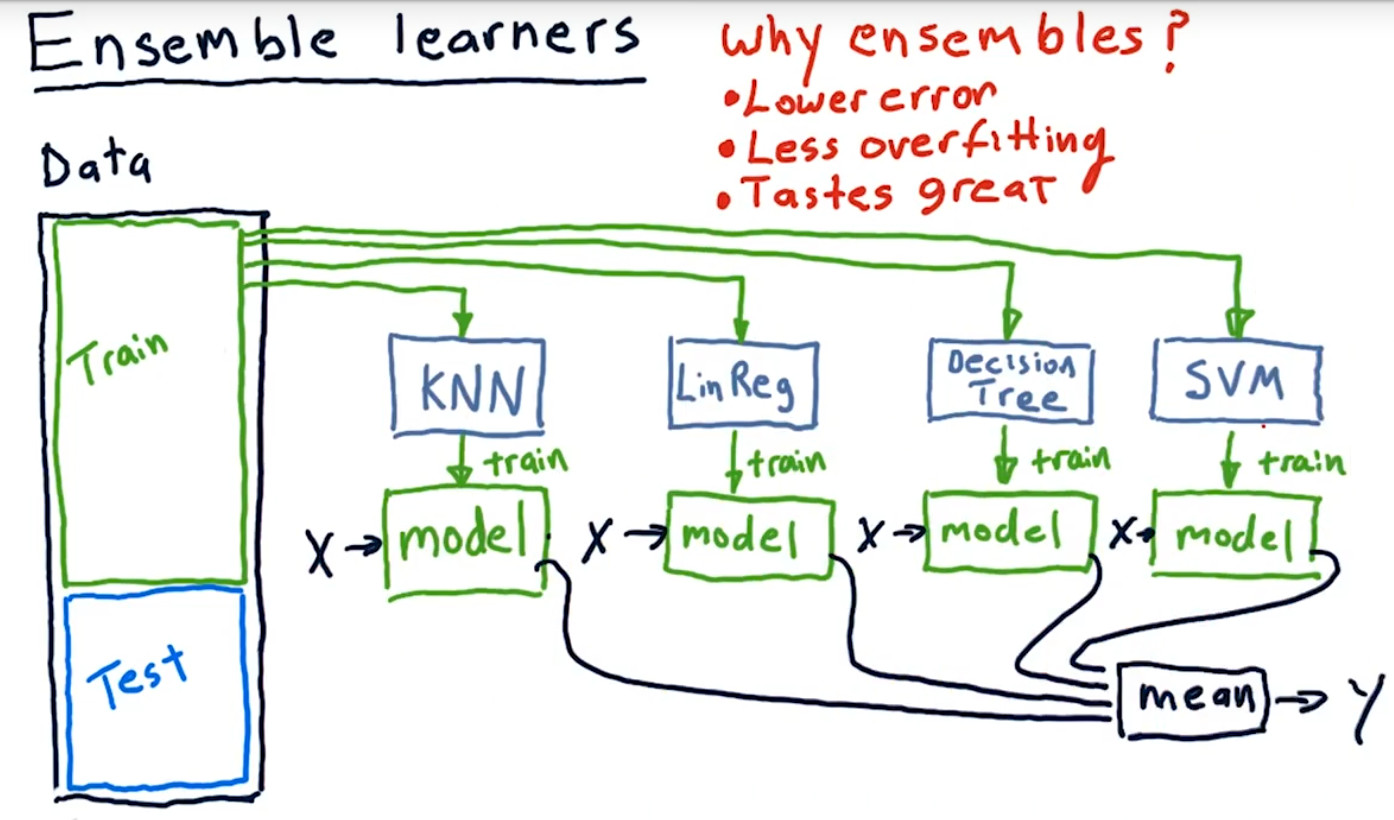
4.ensemble learners
不需要绞尽脑汁去想很复杂的 Rules,只需要一些简单的 Rules,这就是 Ensemble 的基本主张,先找到简单的规则,每一条都有意义,但是单独应用都无法给出最佳答案,然后将这些规则结合起来成为一个 Complex Rule,最后可以找到足够好的答案。
可参考:https://www.jianshu.com/p/d221aa64e295
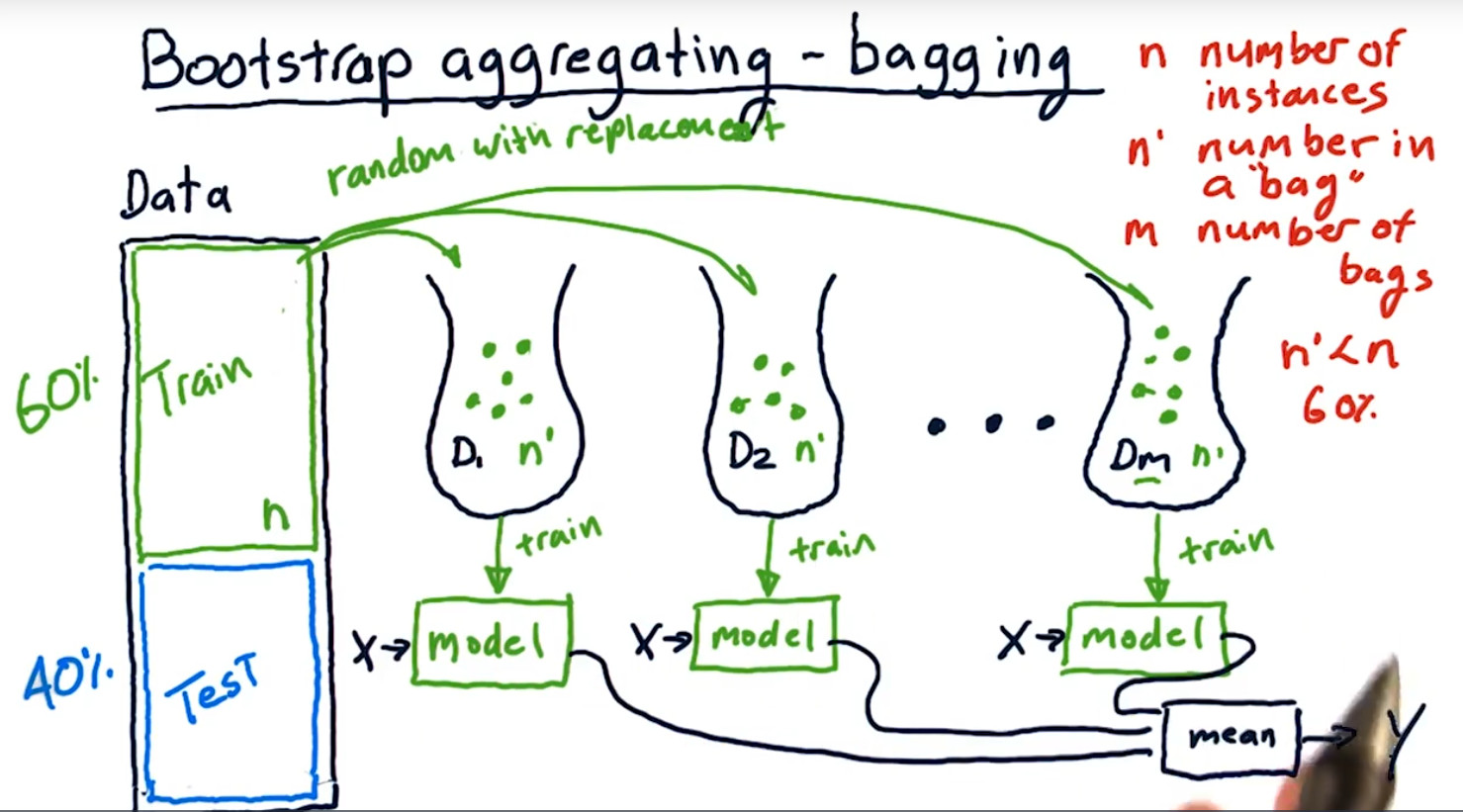
5.bootstrap aggregating or bagging
bagging 是bootstrap aggregating的缩写,中文名叫套袋法。
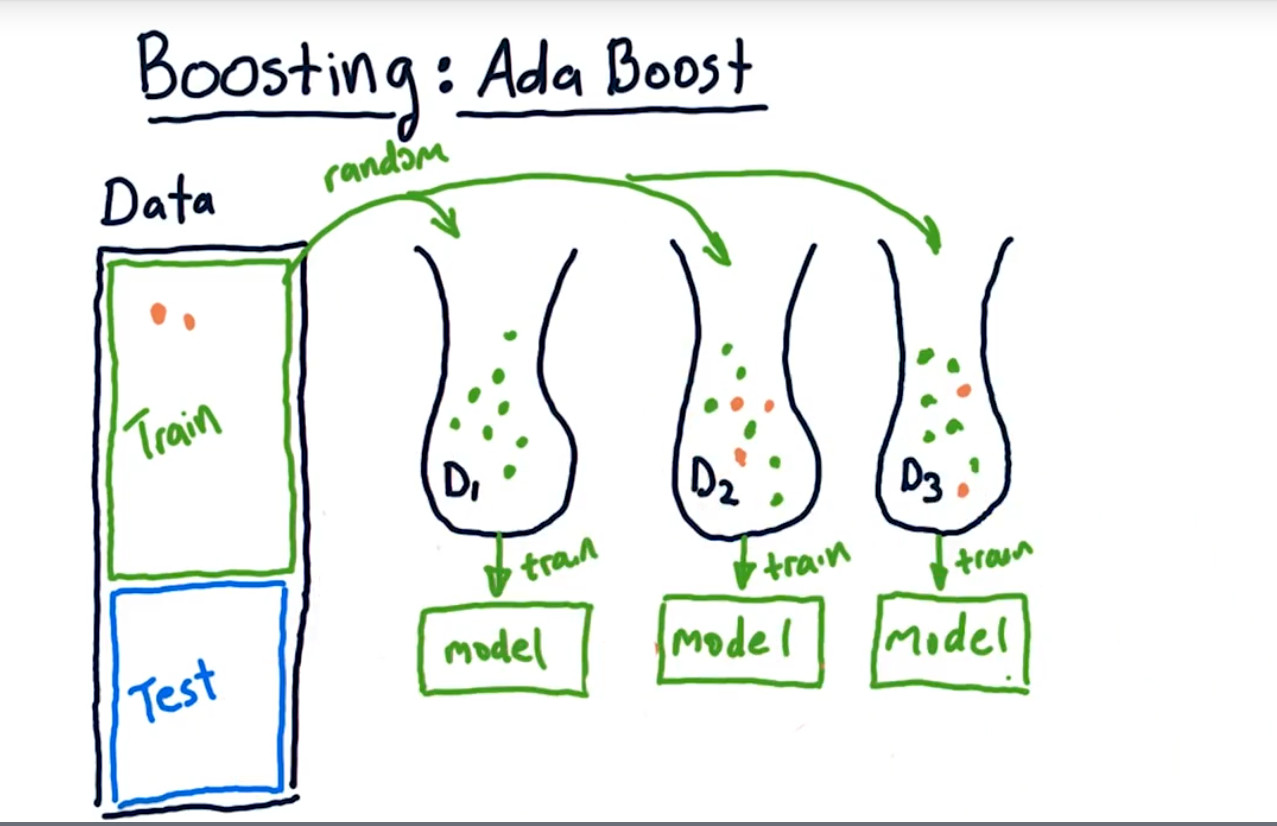
6.Boosting
将bagging稍作变化就是Boosting。
将偏差大的再次放到新的model中。
英语:A disadvantage of UTP is that it may be susceptible to radio and electrical frequency interference
易受...影响
discretize 离散化
heuristic adj. (教学或教育) 启发式的
s' 读作S prime
7.加强学习
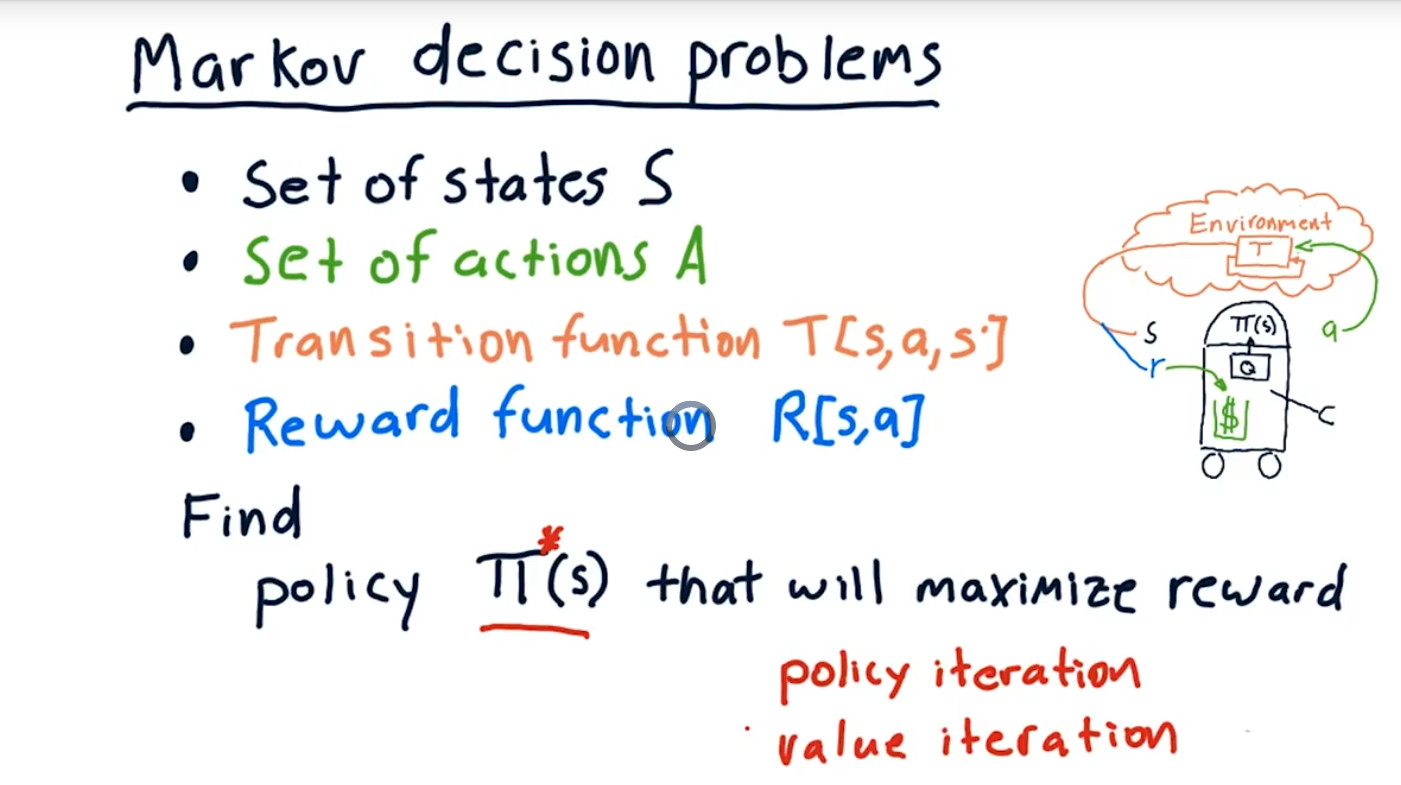

s表示status,a表示Action,
T表示Transition probability, which is given I'm in state s,I take action a.what's the probability it'll end up in state S'.
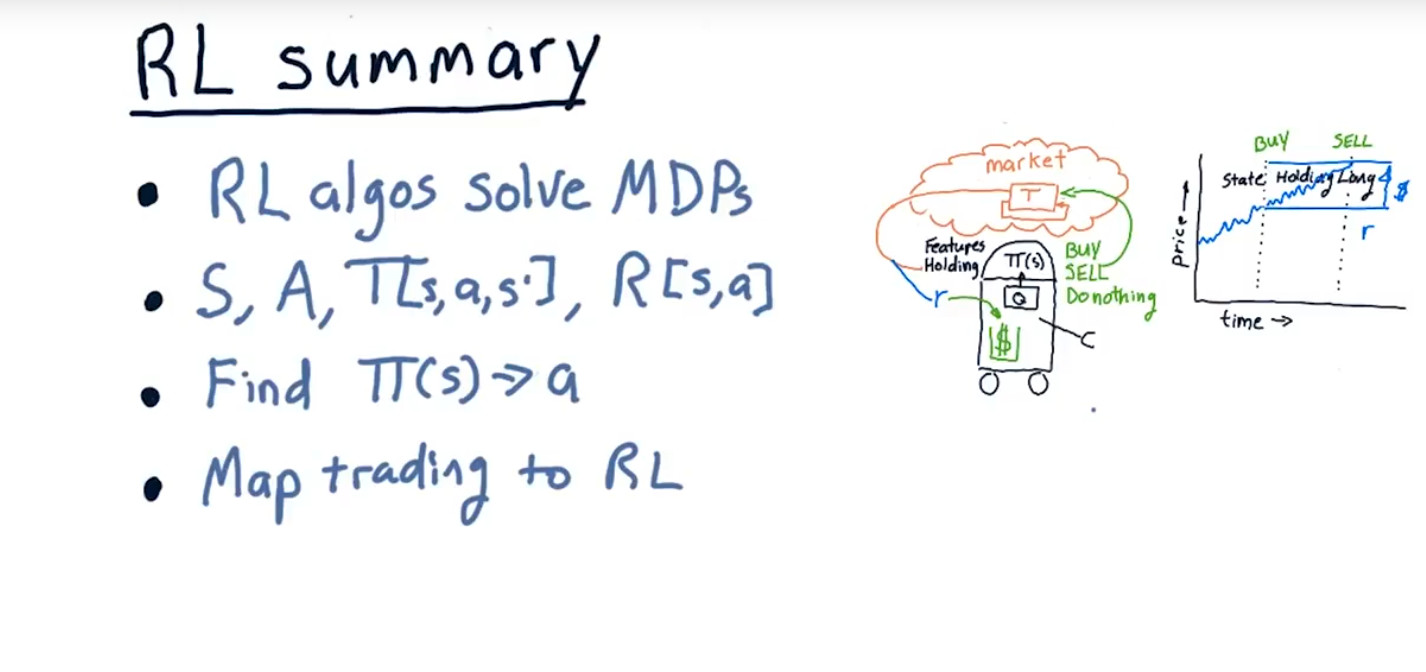
8.Learning-R
R是我们的model,r is what we get in an experience tuple
我们想每次有real experience的时候update我们的model

网址:https://www.udacity.com/course/machine-learning-for-trading--ud501