

备忘:到第37课已经全部学完。
一、一些资源
1.购买数据
https://www.yucezhe.com/product/data/trading
2.采集数据
新浪财经、腾讯财经、东方财富
二、获取实时数据
from urllib.request import urlopen
import pandas as pd
pd.set_option('expand_frame_repr',False) #当列太多时不换行
pd.set_option('display.max_rows',5000) #最多显示数据的行数
#返回一个股票的数据:http://hq.sinajs.cn/list=sh600000
#返回一串股票的数据:http://hq.sinajs.cn/list=sh600000,sz000002,sz300001
stock_code_list = ['sh600000','sz000002','sh600002','sz000003','sz300001']
url = 'http://hq.sinajs.cn/list=' + ','.join(stock_code_list)
content = urlopen(url).read().decode('gbk')
content = content.strip() #去掉文本前后的空格、回车等
date_line = content.split('\n') #每行是一个股票的数据
date_line = [i.replace('var hq_str_','').split(',') for i in date_line]
df = pd.DataFrame(date_line,dtype='float')
print(df)
df[0]=df[0].str.split('="')
df['stock_code'] = df[0].str[0].str.strip()
df['stock_name'] = df[0].str[-1].str.strip()
df['candel_end_time'] = df[30] + ' ' + df[31]
print(df)
执行结果
三、获取日线数据
第32课
from urllib.request import urlopen
import json
from random import randint
import pandas as pd
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 5000)
# =====创建随机数的函数
def _random(n=16):
"""
创建一个n位的随机整数
:param n:
:return:
"""
start = 10**(n-1)
end = (10**n)-1
return str(randint(start, end))
#http://web.ifzq.gtimg.cn/appstock/app/fqkline/get?_var=kline_dayhfq¶m=sh600103,day,,,320,hfq&r=0.9860043111257255
stock_code = 'sz000001'
type = 'day' # day, week, month分别对用日线、周线、月线
num = 640 # 股票最多不能超过640,指数、etf等没有限制
# 构建url
url = 'http://web.ifzq.gtimg.cn/appstock/app/fqkline/get?_var=kline_%sqfq¶m=%s,%s,,,%s,qfq&r=0.%s'
url = url % (type, stock_code, type, num, _random())
content = urlopen(url).read().decode()
content = content.split('=', maxsplit=1)[-1]
content = json.loads(content)
data = content['data'][stock_code]
if type in data:
data = data[type]
elif 'qfq' + type in data: # qfq是前复权的缩写
data = data['qfq' + type]
else:
raise ValueError('已知的key在dict中均不存在,请检查数据')
df = pd.DataFrame(data)
print(df.head())
#对数据进行整理,其中amout单位是手
rename_dict = {0: 'candle_end_time', 1: 'open', 2: 'close', 3: 'high', 4: 'low', 5: 'amount',6: 'info'}
df.rename(columns = rename_dict,inplace = True)
df['candle_end_time'] = pd.to_datetime(df['candle_end_time'])
if 'info' not in df:
df['info'] = None
print(df.head())
执行结果

备注:
获取5分钟数据:http://ifzq.gtimg.cn/appstock/app/kline/mkline?param=sh600020,m5,,800&_var=m5_today
四、对股票进行复权
import pandas as pd
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 5000)
path = "E:\\stock\\01\\data\\sz300001_sample.csv"
df = pd.read_csv(path,encoding = 'gbk',skiprows = 0)
#计算复权涨跌幅
df['涨跌幅'] = df['收盘价']/df['前收盘价']-1
#计算复权因子:假设你一开始有1元钱,投资到这个股票,最终会变成多少钱
df['复权因子'] = (1+df['涨跌幅']).cumprod()
#计算后复权价
df['收盘价_后复权']=df['复权因子']*(df.iloc[0]['收盘价']/df.iloc[0]['复权因子'])
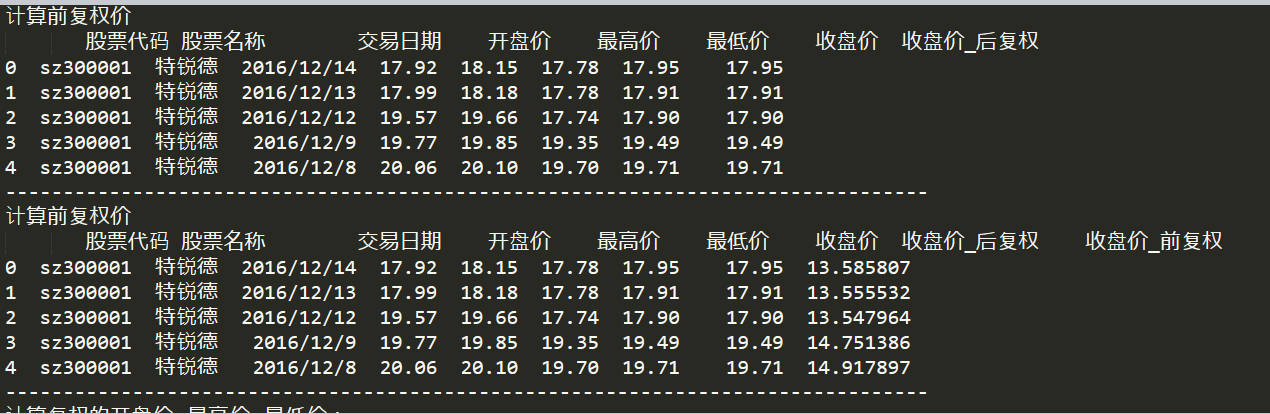
print("计算后复权价")
print(df[['股票代码','股票名称','交易日期','开盘价','最高价','最低价','收盘价','收盘价_后复权']].head())
print("-"*80)
#计算后复权价另一种计算方法:
#initial_price = df.iloc[0]['收盘价'] / (1 + df.iloc[0]['涨跌幅']) # 计算上市价格
#df['收盘价_后复权'] = initial_price * df['复权因子'] # 相乘得到复权价
#计算前复权价
df['收盘价_前复权']= df['复权因子'] *(df.iloc[-1]['收盘价']/df.iloc[-1]['复权因子'])
print("计算前复权价")
print(df[['股票代码','股票名称','交易日期','开盘价','最高价','最低价','收盘价','收盘价_后复权','收盘价_前复权']].head())
print("-"*80)
#计算复权的开盘价、最高价、最低价
df['开盘价_复权'] = df['开盘价']/df['收盘价']*df['收盘价_后复权']
df['最高价_复权'] = df['最高价']/df['收盘价']*df['收盘价_后复权']
df['最低价_复权'] = df['最低价']/df['收盘价']*df['收盘价_后复权']
print("计算复权的开盘价、最高价、最低价:")
print(df.head())
#df.to_csv('output_fuquan_sz300001.csv',index=False,mode='w',float_format='%.15f',header=None,encoding='gbk')
执行结果:
五、对所有股票数据进行采集
通过下面的代码,可以每天将上证的所有股票日线数据采集下来,并且存储到自己电脑的csv文件,方便以后调用。
import os
import json
import pandas as pd
from datetime import datetime
import time
import re
from urllib.request import urlopen
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 5000)
def get_content_from_internet(url,max_try_num=10,sleep_time=5):
get_success = False
for i in range(max_try_num):
try:
content = urlopen(url=url,timeout=10).read()
get_success = True
break
except Exception as e:
print("抓取数据报错次数:",i+1,"报错内容:",e)
time.sleep(sleep_time)
#判断是否成功抓取内容
if get_success:
return content
else:
raise ValueError("使用urlopen抓取网页数据不断报错,达到尝试上限,停止程序,请尽快检查。")
def get_today_data_from_sinajs(code_list):
url = 'http://hq.sinajs.cn/list=' + ','.join(code_list)
content = get_content_from_internet(url)
content = content.decode('gbk')
#将数据转换成DataFrame
content = content.strip() #去掉文本前后的空格、回车等
date_line = content.split('\n') #每行是一个股票的数据
date_line = [i.replace('var hq_str_','').split(',') for i in date_line]
df = pd.DataFrame(date_line,dtype='float')
#对DateFrame进行整理
df[0]=df[0].str.split('="')
df['stock_code'] = df[0].str[0].str.strip()
df['stock_name'] = df[0].str[-1].str.strip()
df['candle_end_time'] = df[30] + ' ' + df[31]
df['candle_end_time'] = pd.to_datetime(df['candle_end_time'])
#amount单位是手,volume是元
rename_dict = { 1: 'open', 2: 'pre_close', 3: 'close', 4: 'high', 5: 'low',6:'buy1',7:'sell1',8: 'amount',9:'volume',32:'status'}
df.rename(columns = rename_dict,inplace = True)
# df['status']=df['status'].str.strip('";')
df = df[['stock_code','stock_name','candle_end_time','open','high','low','close','pre_close','amount','volume','buy1','sell1','status']]
return df
print(df)
#http://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page=1&num=40&sort=symbol&asc=1&node=cyb&_s_r_a=init
#http://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page=1&num=40&sort=symbol&asc=1&node=hs_a&symbol=_s_r_a=sort
def get_all_today_stock_data_from_sina_marketcenter():
raw_url = "http://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page=%s&num=40&sort=symbol&asc=1&node=hs_a&symbol=_s_r_a=sort"
page_num = 1
#存储数据的dataframe
all_df = pd.DataFrame()
#开始逐页遍历,获取股票数据
while True:
url = raw_url % (page_num)
print("开始抓取页数:",page_num)
#抓取数据
content = get_content_from_internet(url)
content = content.decode('gbk')
if 'null' in content:
print("抓取到页数的尽头,退出循环。")
break
#通过正则,将key加上引号
content = re.sub(r'(?<={|,)([a-zA-Z][a-zA-Z0-9]*)(?=:)',r'"\1"',content)
#将数据转换成dict格式
content = json.loads(content)
df = pd.DataFrame(content)
#添加交易日期
df['trade_date'] = pd.to_datetime(datetime.now().date())
#取需要的列,trade是收盘价,settlement是前收,volume不是手,是股,amount是元
df = df[['code','name','trade_date','open','high','low','trade','settlement','volume','amount']]
#合并数据
all_df = all_df.append(df,ignore_index=True)
return all_df #加了这一句,只采集第1页
page_num+=1
time.sleep(1)
exit()
# return all_df
#判断今天是否是交易日
def is_today_trading_day():
#获取上证指数今天的数据
df = get_today_data_from_sinajs(code_list=['sh000001'])
sh_date = df.iloc[0]['candle_end_time'] #上证指数最近交易日
#判断今天日期和sh_date是否相同
return datetime.now().date() == sh_date.date()
if is_today_trading_day() is False:
print("今天不是交易日,不需要更新股票数据,退出程序")
exit()
if datetime.now().hour < 15: #保险起见可以小于16
print('今天股票尚未收盘,不更新股票数据,退出程序')
exit()
# df = get_today_data_from_sinajs(code_list=['sh600000'])
# print(df)
df = get_all_today_stock_data_from_sina_marketcenter()
#对股票进行存储:
for i in df.index:
t = df.iloc[i:i+1,:]
stock_code = t.iloc[0]['code']
#构建存储文件
path = 'E:\\stock\\01\\mydata\\'+stock_code + '.csv'
#文件存在,不是新股
if os.path.exists(path):
t.to_csv(path,header= None,index = False,mode='a',encoding='gbk')
else:
#文件不存在
#先将头文件输出
pd.DataFrame(columns = ["数据由xx整理"]).to_csv(path,index=False,encoding='gbk')
t.to_csv(path,index = False,mode='a',encoding='gbk' )
print(stock_code+"数据存储成功")