

一、贝叶斯定理
分类问题是一种经典的机器学习问题,而贝叶斯只是一种常见模型。比如最朴素的分类模型和最容易理解的模型其实是决策树模型,这种模型比较接近我们的决策思维。
主要思路是根据与我们解决问题相关的多个因素逐一确定下一步的方案,整个决策过程就像一棵自顶向下的树一样,故名决策树。如图2-1所示,这是一个人根据天气、温度、风况和气压几个因素决定是否去钓鱼的决策树。
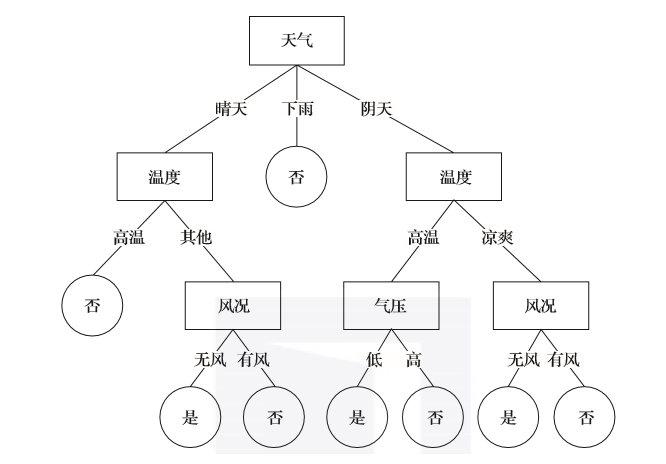
图中矩形的节点是决策节点,节点之间连线上的是属性值,而圆形节点是结果节点。
构建完这个树模型之后我们就可以预测这个人是否会出门钓鱼了。预测时,首先我们把数据输入到根节点。其次,根据数据属性值来选择某个特定的分支,每选择一个子节点再根据该节点分支的属性值选择该节点的特定分支,直到递归遍历到叶子节点为止,就可以得到预测结果了。
这个模型比较符合我们解决问题的逻辑思维,易于理解,因此常常会用在专家系统中。另外,这个模型需要存储的参数相对较少,预测耗时短,这也是它的优点。
但是决策树其实远不止这么简单,常用的决策树算法有ID3算法、C4.5算法、CART算法和随机森林等,由于本章重点不是决策树,因此这里就不过多阐述了,有兴趣的读者可以自行查阅相关资料。
现在让我们进入正题:贝叶斯模型。贝叶斯思想的最初提出者如下图所示——18世纪英国数学家托马斯·贝叶斯(Thomas Bayes)。
贝叶斯模型的核心思想是贝叶斯定理,这源于他生前为解决一个“逆概”问题而写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。
在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一次,摸出黑球的概率是多少”。
而逆向概率问题是相反的一类问题,比如“如果事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,我们如何推测此袋子里面的黑白球的比例?”
贝叶斯定理的思想出现在18世纪,但真正大规模使用发生在计算机出现之后。因为这个定理需要大规模的数据计算推理才能体现效果,它在很多计算机应用领域中都大有作为,如自然语言处理、机器学习、推荐系统、图像识别、博弈论,等等。
那么,我们可以使用贝叶斯模型来解决什么现实问题呢?以下是一个经典的彩球抽奖问题。
这是一个猜谜拿奖游戏,已知有A、B两个桶,A中有红球3个,白球1个;B中有红球2个,白球2个。现在我们随机选择一个桶,每次取出一个球并放回,判断反复4次后该桶是A还是B。
这其实是一个以小见大的问题。就像我们看现实世界,总是只能看到这个现实世界中的一部分表现形式(摸到了几个球或是什么颜色),但是不知道这个表现形式后面的本质(到底是哪一个桶)。当面对这类问题的时候贝叶斯模型就非常有用了。
贝叶斯模型是所有使用贝叶斯定理思想的模型的统称,本文主要讲解最简单的朴素贝叶斯分类器。不过考虑到可能有读者不太熟悉或者忘记了概率论,我们先来回顾一下基本概率论知识,这样才能理解贝叶斯定理。
第1个概念是先验概率。首先我们将A事件发生的概率写作P(A),称之为A的先验概率。所谓先验概率,就是根据以往的经验得到的概率。那么P(B)就是B的先验概率了。如果用文氏图表示,图2-3中A圈就表示A事件的样本集合,B圈就是B事件的样本集合。

▲图2-3 样本文氏图(1)
第2个概念是条件概率。所谓条件概率就是在另一个事件发生的条件下,某事件发生的概率,比如P(A|B)表示在B事件发生的条件下,A发生的概率;而P(B|A)就是在A事件发生条件下,B事件发生的概率。然后还有一个概念是联合概率,比如P(A∩B)表示A和B事件同时发生的概率。
我们来看图2-4,其中A和B交叉的部分就是A和B的联合概率,那么条件概率呢?就是交叉部分在A和B圈子里各占的比例,如果在A里,就是A事件发生情况下B事件发生的概率,如果在B里则反之。
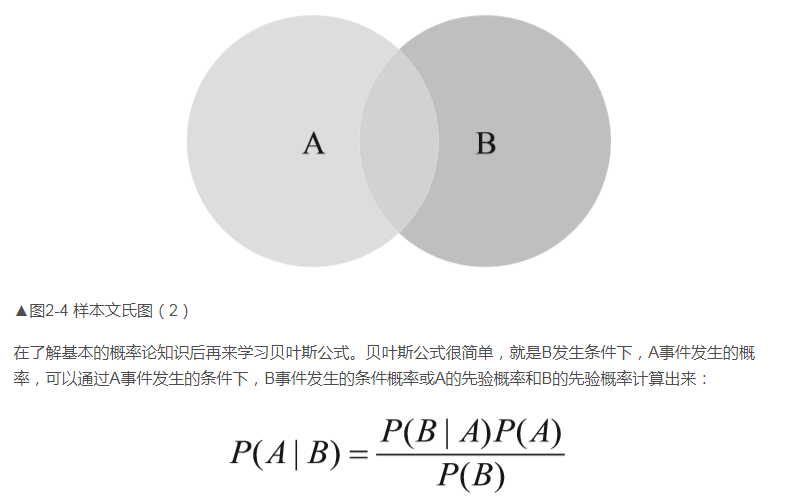
在了解基本的概率论知识后再来学习贝叶斯公式。贝叶斯公式很简单,就是B发生条件下,A事件发生的概率,可以通过A事件发生的条件下,B事件发生的条件概率或A的先验概率和B的先验概率计算出来:
那么这个公式到底有什么用呢?
举个例子,假如我们想要检查邮箱中是否存在垃圾邮件,最简单的方法是根据邮件中是否存在某些关键词来做判断。但实际情况是,并不是所有涉及某个关键词的邮件都是垃圾邮件。所以我们就可以做出一个假设:垃圾邮件中关键词的出现频率是有规律的。
根据这个假设,我们可以收集一批垃圾邮件和一批正常邮件,统计一下所有邮件中包含关键词的频率,垃圾邮件的出现频率以及关键词在垃圾邮件中的出现频率。
其中
P(A)是垃圾邮件的出现频率,
P(B)是关键词的出现频率,
P(B|A)就是垃圾邮件中的关键词出现频率。
那么由贝叶斯公式我们就可以推算出P(A|B),也就是存在特定关键词时某封邮件是垃圾邮件的概率了。
(要求特定关键词时某封邮件是垃圾邮件的概率,也就是P(A|B)=> P(B)是关键词的出现频率,P(A)是垃圾邮件的的频率。=>要求出P(B|A),即垃圾邮件中的关键词出现频率。
我们知道,我们平时只能观测到现实中某些现象的表现形式,正如我们只能知道垃圾邮件中关键词的出现频率。但是,我们总是希望能够通过现象去推断出事物的本质,而贝叶斯模型正是这种模型,让我们可以通过某些容易计算的概率去了解某些事物内在性质的概率。而通过收集大量的数据,则可以让贝叶斯这种概率类的模型更加准确。
不过这里还有个问题,在实际情况中会有很多的属性(也就是特征),比如判断一封邮件是不是垃圾邮件,肯定不只有一个关键词,因此我们要考虑所有可能关键词出现的概率。
这个问题怎么处理呢?这个时候我们就要对公式进行变换,需要计算在B1~Bn多个事件同时发生的概率下A事件发生的概率(也就是根据多个关键词的出现概率估算某封邮件是垃圾邮件的概率)。
这里的难点在于样本量比较小,在这种情况下如果直接估算B1到Bn的联合概率会导致存在比较大的误差。所以,贝叶斯公式给出了一个假设:假设各个事件之间是相互独立的,也就是不同的属性会独立地对最后的分类结果产生影响。
所以这里我们就可以将联合概率变成多个事件概率的乘积,那个大大的类似于π的符号就是累乘符号,就像之前提到的累加符号一样,是一种数学符号的简写:
这个推广后的公式就是朴素贝叶斯分类器的核心。思考一下,假如我们有大量的邮件,里面同时包含垃圾邮件和正常邮件,我们只要分别估算不同的敏感词的概率,最后就能计算得到某封邮件是垃圾邮件的概率,而利用朴素贝叶斯解决其他的问题也是同一个套路。
虽然看起来都是数学,但是用起来还是非常简单的。我们可以用朴素贝叶斯分类器处理前面所提到的抽奖问题。我们可以通过计算知道:
P(A):摸到红球的概率是5/8。
P(B):选择A桶的概率是1/2。
P(A|B):在A桶中摸到红球的概率3/4。
假设摸到一个红球,选择到A桶的概率为:

所以如果我们摸到2个红球,2个绿球,只需要带入到上面那个推广后的公式里就可以得到结果了。我们提前训练得到的知识就是摸到红球的概率、摸到绿球的概率、在A中摸到红球或者绿球的概率以及在B中摸到红球或者绿球的概率。
作者:卢誉声
来源:大数据DT(ID:hzdashuju)
二、贝叶斯在机器学习中的使用
在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树,KNN,逻辑回归,支持向量机等,他们都是判别方法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y|X)。但是朴素贝叶斯却是生成方法,也就是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出。朴素贝叶斯很直观,计算量也不大,在很多领域有广泛的应用。
2、scikit-learn 朴素贝叶斯类库
朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的,这样也比较容易掌握。在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
这三个类适用的分类场景各不相同,主要根据数据类型来进行模型的选择。一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
a>>>GaussianNB Naive_Bayes
GaussianNB类的主要参数仅有一个,即先验概率priors,对应Y的各个类别的先验概率P(Y=Ck)。这个值默认不给出,如果不给出此时P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。如果给出的话就以priors 为准。 在使用GaussianNB的fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。
predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。
predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。
predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。
此外,GaussianNB一个重要的功能是有 partial_fit方法,这个方法的一般用在如果训练集数据量非常大,一次不能全部载入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步的学习训练集,非常方便。后面讲到的MultinomialNB和BernoulliNB也有类似的功能。
b>>>MultinomialNB Naive_Bayes
MultinomialNB参数比GaussianNB多,但是一共也只有仅仅3个。其中,参数alpha即为上面的常数λ,如果你没有特别的需要,用默认的1即可。如果发现拟合的不好,需要调优时,可以选择稍大于1或者稍小于1的数。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。

c>>>BernoulliNB Naive_Bayes
BernoulliNB一共有4个参数,其中3个参数的名字和意义和MultinomialNB完全相同。唯一增加的一个参数是binarize。这个参数主要是用来帮BernoulliNB处理二项分布的,可以是数值或者不输入。如果不输入,则BernoulliNB认为每个数据特征都已经是二元的。否则的话,小于binarize的会归为一类,大于binarize的会归为另外一类。
在使用BernoulliNB的fit或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。由于方法和GaussianNB完全一样,这里就不累述了。
上面的说法还是说得不太明白,还是看这个吧:

3、朴素贝叶斯的主要优缺点
朴素贝叶斯的主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。
参考:https://blog.csdn.net/brucewong0516/article/details/78798359
三、实践
(一)Predicting survival from titanic crash(预测泰坦尼克号的存活率)
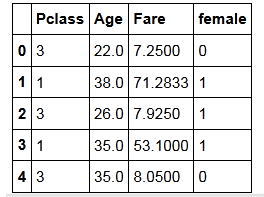
通过下面的因素来预测泰坦尼克号存活率

最终用到的因素
1.代码
import pandas as pd
df = pd.read_csv("titanic.csv")
df.drop(['PassengerId','Name','SibSp','Parch','Ticket','Cabin','Embarked'],axis='columns',inplace=True)
inputs = df.drop('Survived',axis='columns')
target = df.Survived
dummies = pd.get_dummies(inputs.Sex)
inputs = pd.concat([inputs,dummies],axis='columns')
# print(inputs.head(3))
inputs.drop(['Sex','male'],axis='columns',inplace=True)
inputs.columns[inputs.isna().any()]
inputs.Age = inputs.Age.fillna(inputs.Age.mean())
# print(inputs.head())
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(inputs,target,test_size=0.3)
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train,y_train)
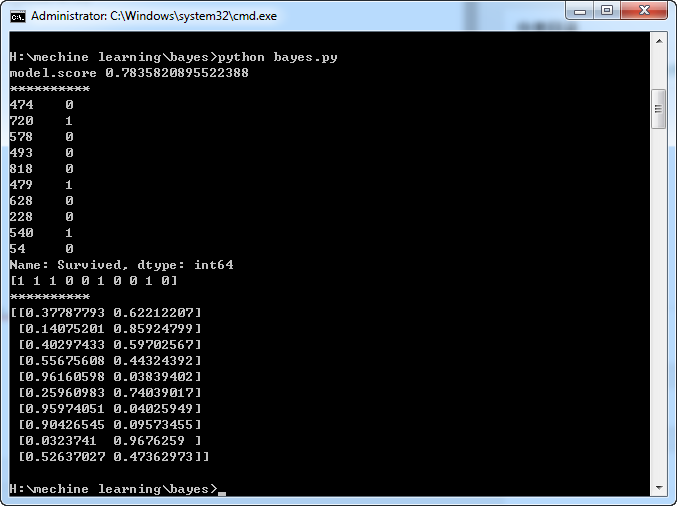
print("model.score",model.score(X_test,y_test))
print("*"*10)
print(y_test[0:10])
print(model.predict(X_test[0:10]))
print("*"*10)
print(model.predict_proba(X_test[:10]))
2.结果
参考:
https://www.youtube.com/watch?v=PPeaRc-r1OI
(二)email_spam_filter(垃圾邮件识别)
关于向量化。

1.代码
import pandas as pd
df = pd.read_csv("spam.csv")
# print(df.groupby('Category').describe())
df['spam']=df['Category'].apply(lambda x: 1 if x=='spam' else 0) #将文字转化为数字
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.Message,df.spam)
from sklearn.feature_extraction.text import CountVectorizer
v = CountVectorizer()
X_train_count = v.fit_transform(X_train.values)
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train_count,y_train)
emails = [
'Hey mohan, can we get together to watch footbal game tomorrow?',
'Upto 20% discount on parking, exclusive offer just for you. Dont miss this reward!'
]
emails_count = v.transform(emails)
print("预测结果:",model.predict(emails_count))
X_test_count = v.transform(X_test)
print("预测准确率:",model.score(X_test_count, y_test))
代码二,通过pipeline简化代码
import pandas as pd
df = pd.read_csv("spam.csv")
# print(df.groupby('Category').describe())
df['spam']=df['Category'].apply(lambda x: 1 if x=='spam' else 0) #将文字转化为数字
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.Message,df.spam)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
clf = Pipeline([
('vectorizer', CountVectorizer()),
('nb', MultinomialNB())
])
clf.fit(X_train, y_train)
emails = [
'Hey mohan, can we get together to watch footbal game tomorrow?',
'Upto 20% discount on parking, exclusive offer just for you. Dont miss this reward!'
]
print(clf.score(X_test,y_test))
print(clf.predict(emails))
2.结果

参考:
https://www.youtube.com/watch?v=nHIUYwN-5rM
https://github.com/codebasics/py/tree/master/ML/14_naive_bayes