

学习目标:
- 通过抓取一个博客的标题,进一步了解利用Scrapy抓取数据的流程
测试环境:
win7 旗舰版
Python 2.7.14(Anaconda2 2 5.0.1 64-bit)
一、创建项目
进入“Anaconda Prompt”的窗口,输入以下命令:
scrapy startproject scrapyspider
二、编写第一个爬虫(Spider)
在scrapyspider/spiders目录下建立一个名为blog_spider.py的文件。
输入以下代码:
from scrapy.spiders import Spider
class BlogSpider(Spider):
name = 'woodenrobot'
start_urls = ['http://woodenrobot.me']
def parse(self, response):
titles = response.xpath('//a[@class="post-title-link"]/text()').extract()
for title in titles:
print title.strip()
其中:
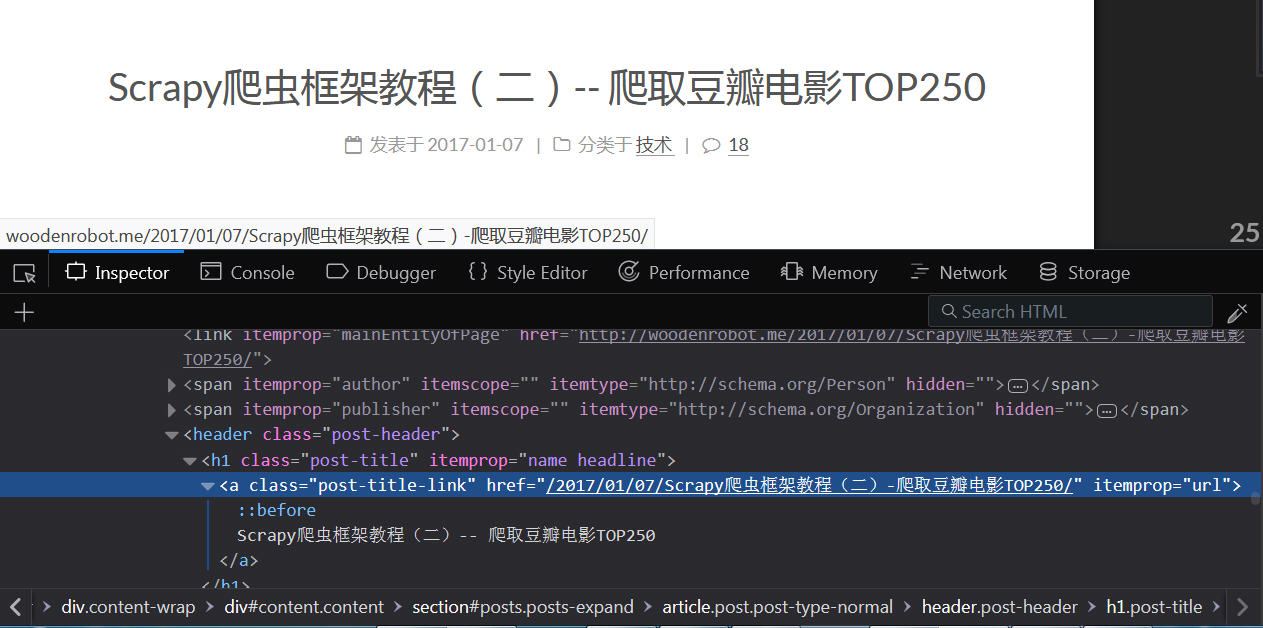
titles = response.xpath('//a[@class="post-title-link"]
这句的意思是选取所有具有class="post-title-link"属性的A元素的值。
关于xpath的介绍,可以看这里
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
三、启动爬虫
进入项目所在根目录,即scrapyspider路径下,运行:scrapy crawl woodenrobot命令。
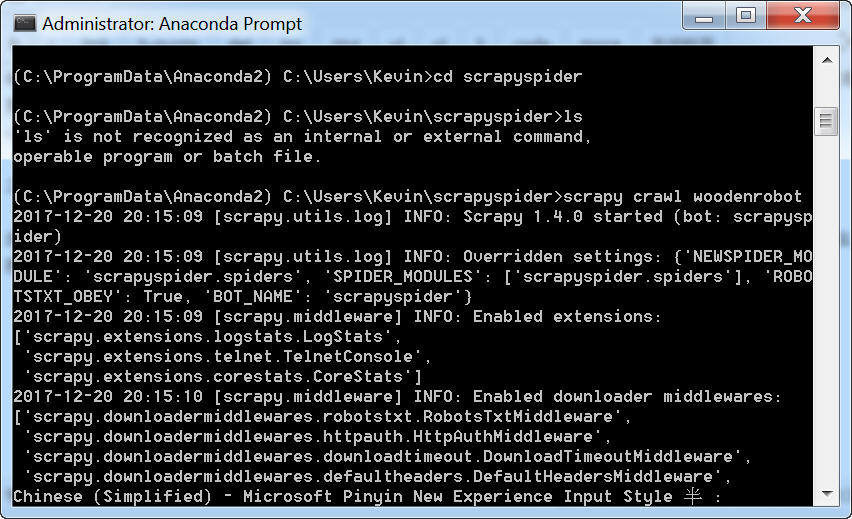
就可以看到爬虫抓取当前页所有文章标题了。

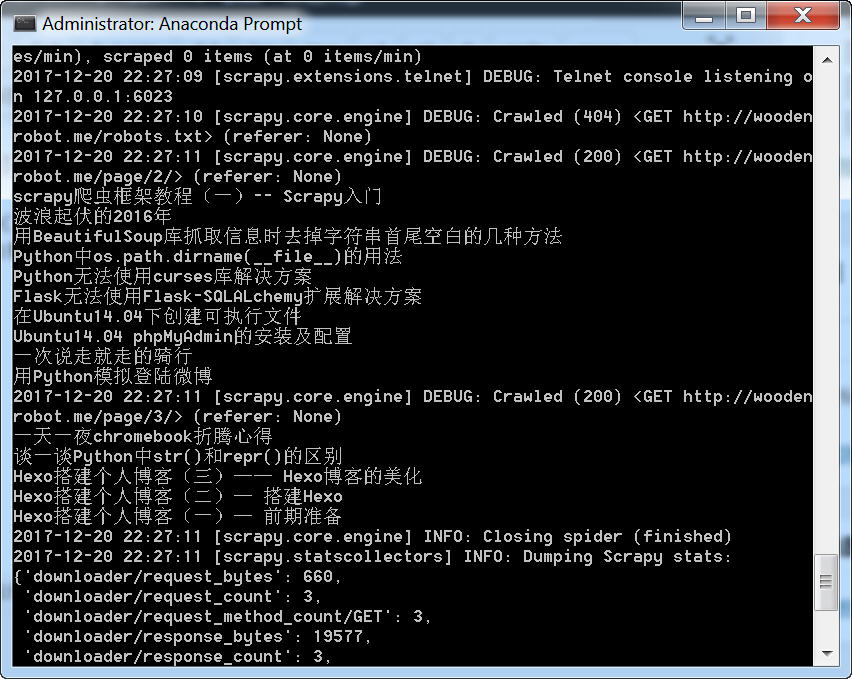
四、抓取多页内容
将start_urls的那一段代码改成:
start_urls = [
'http://woodenrobot.me/page/2/',
'http://woodenrobot.me/page/3/',
]
即使我们没有加以下代码:
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
parse()也会自动处理每个URLs的返回数据,因为parse() 是Scrapy默认的callback方法,如果没有指定callback的方法,就自动使用parse()。
运行的效果图:
五、保存数据
将for title in titles后面的代码改成:
for title in titles:
yield {
'Title': title,
}
然后执行下面的命令,就会在项目的根目录下面,生成一个CSV文件:
scrapy crawl woodenrobot -0 woodenrobot.csv
将最后面的csv改成json,则可以生成Json文件。
不过由于编码的原因,CSV、Json文件打开都是乱码。
csv文件用记事本打开反而不是乱码了。
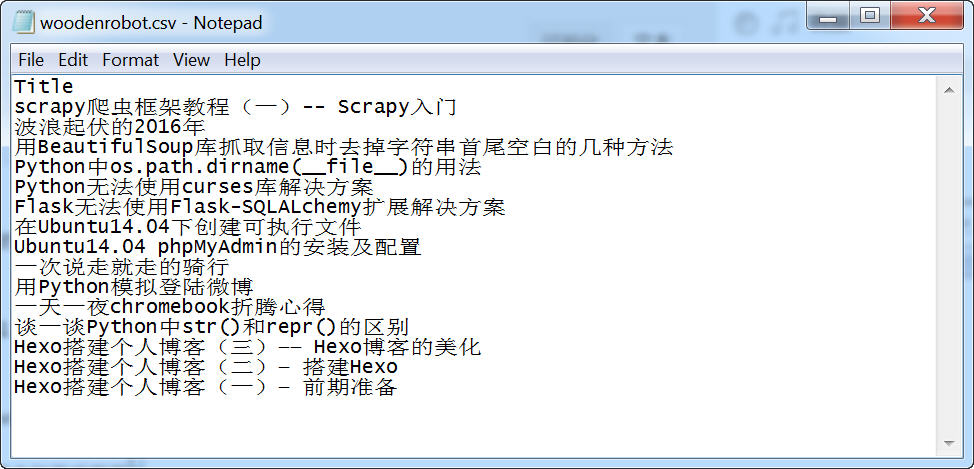
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。