

测试环境:
win7 旗舰版
Python 2.7.14(Anaconda2 2 5.0.1 64-bit)
学习目标:
- 掌握利用Ipython的命令行模式新建Sqlite数据库、数据表的方法
- 掌握PyCharm关联Sqlite数据库的方法
- Python中文乱码的解决方法
- 掌握将采集的数据插入Sqlite数据库的方法
一、新建项目
新建项目之后,用PYcharm打开这个项目。
二、撰写爬虫文件
在spider文件夹下面新建一个ganji.py文件,
输入以下代码:
import scrapy
class GanjiSpider(scrapy.Spider):
name="zufang"
start_urls = ['http://bj.ganji.com/fang1/chaoyang/']
def parse(self,response):
print(response)
title_list = response.xpath(".//div[@class='f-list-item ershoufang-list']/dl/dd[1]/a/text()").extract()
money_list = response.xpath(".//div[@class='f-list-item ershoufang-list']/dl/dd[5]/div[1]/span[1]/text()").extract()
for i,j in zip(title_list,money_list):
print(i,":",j)
小技巧:
在提取网页元素的Xpath路径的时候,我们可以使用F12键打开Chrome浏览器的开发者工具,然后直接复制出Xpath路径即可。
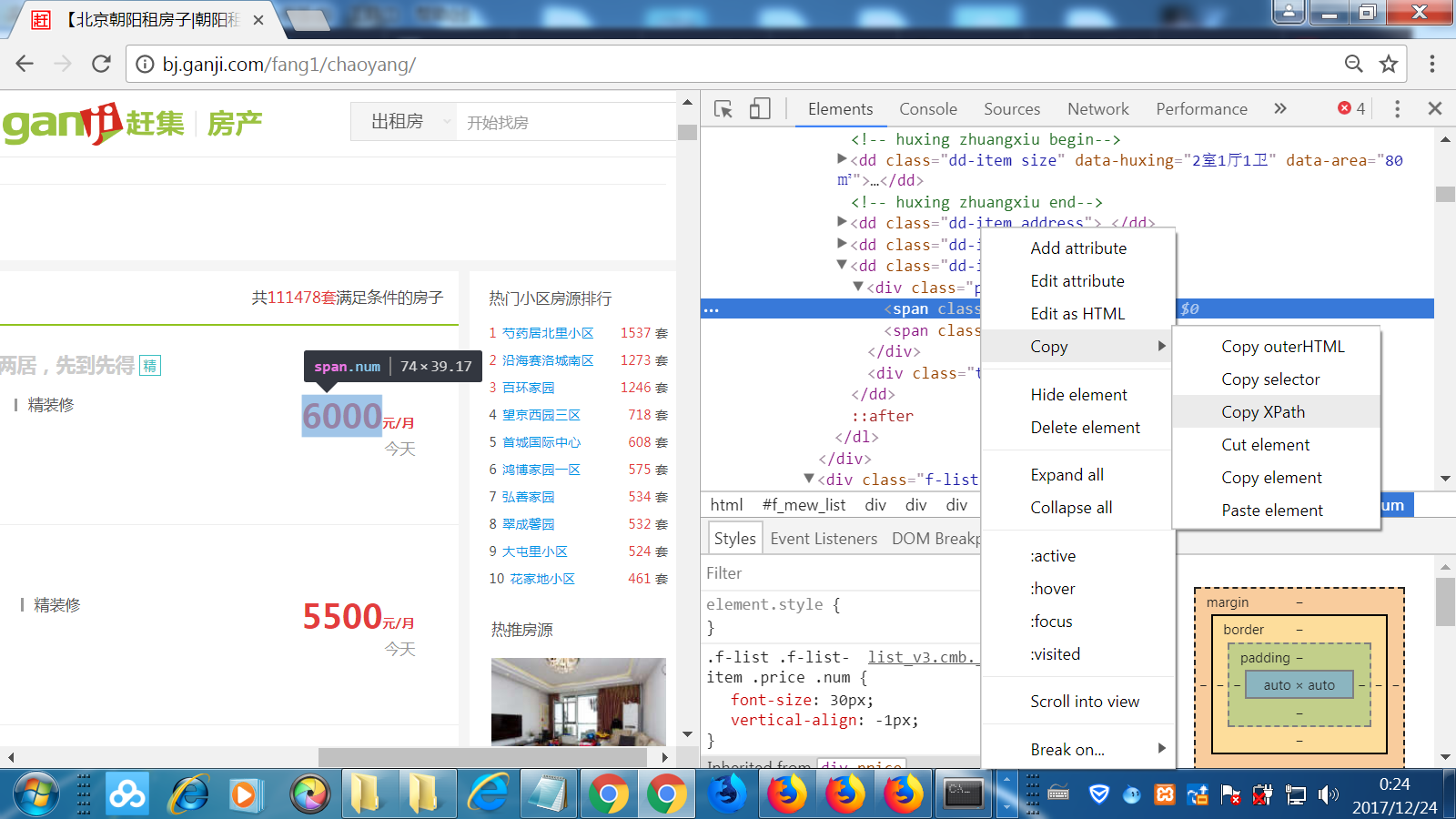
不知怎么回事,chrome和firefox复制的xpath路径不一致:
firefox:
/html/body/div[7]/div[1]/div[3]/div[1]/div[1]/dl/dd[5]/div[1]/span[1]
chrome:
//*[@id="puid-2979453203"]/dl/dd[5]/div[1]/span[1]
不过还是chrome的满足我的需要。
三、SQlite数据库操作
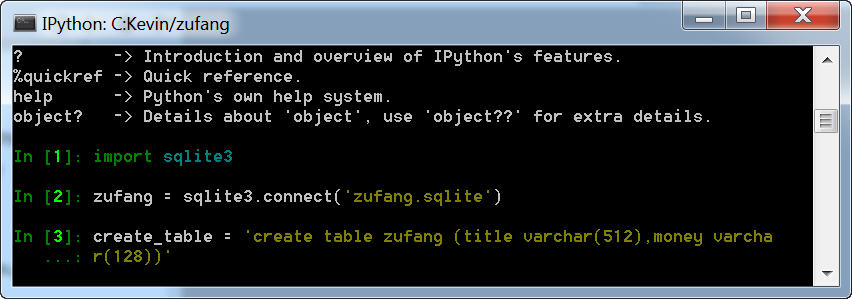
1、进入Python命令模式
输入Ipython,进入Ipython(输入前请检查操作目录是在zufang项目的根目录下)。
2、新建数据库。
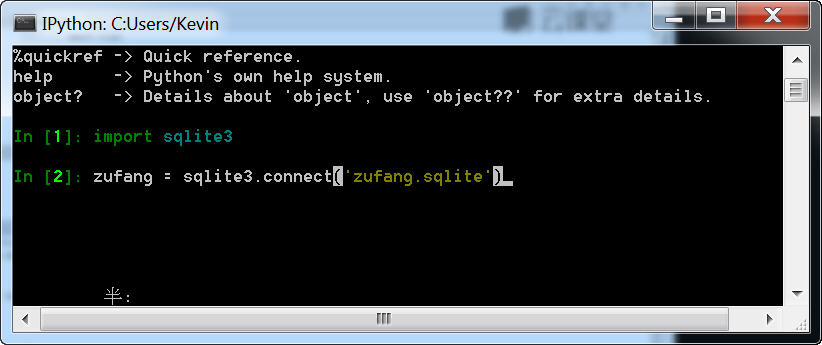
这时会发现,zufang根目录下多了一个zufang.sqlite文件。
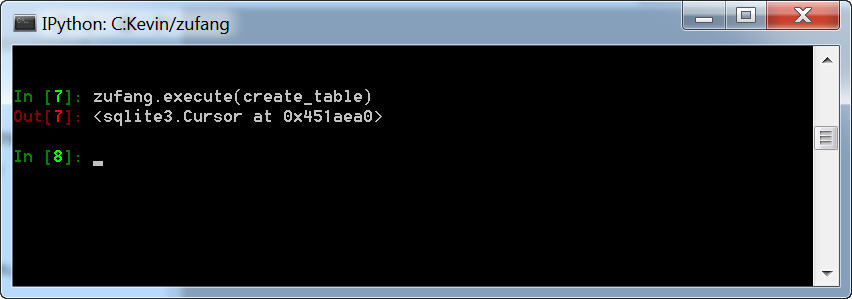
3、创建表格
4、打开Database
在Pycharm中,通过“view-tool windows-database”打开数据库窗格。
如果你用的是社区版的Pycharm,那么通过“打开File—》Settings—-》Plugins搜索database”,选择Database Navigator安装即可。
然后从左边的窗格中将zufang.sqlite文件拖到Database的窗格中。
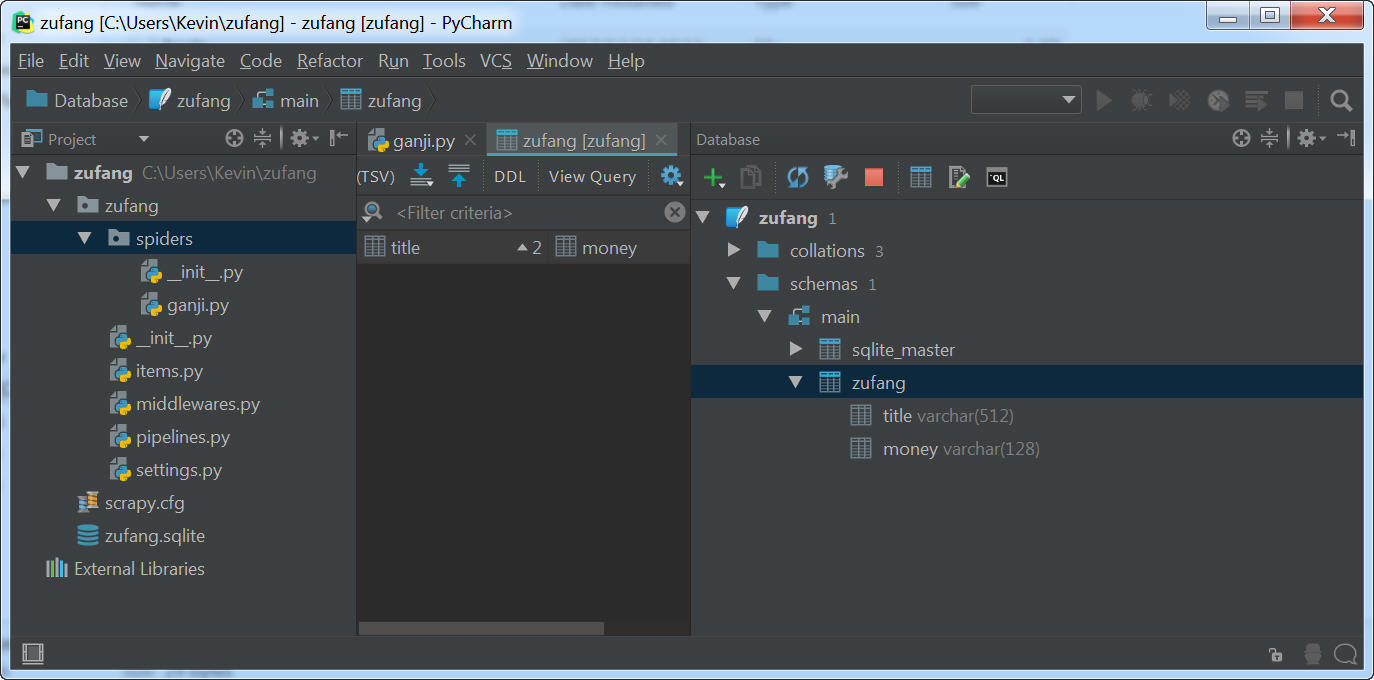
现在在Pycharm的窗格中点开zufang.sqlite,就可以看到刚刚我们创建的表了。
小技巧:
如果无法展开zufang.sqlite,可以按下面的步骤测试一下数据库连接。
1、打开pycharm IDE

2、下载驱动
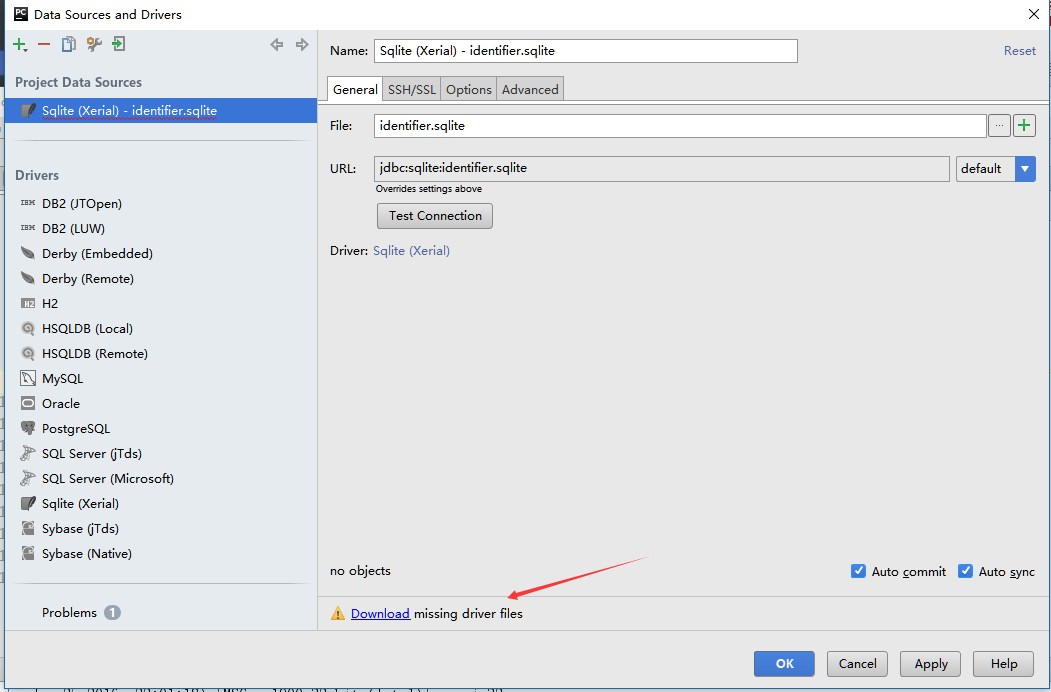
直到提示信息变成:no objects
3、测试连接
找到自己的zufang.sqlite数据库,点击“Test Connection ”。
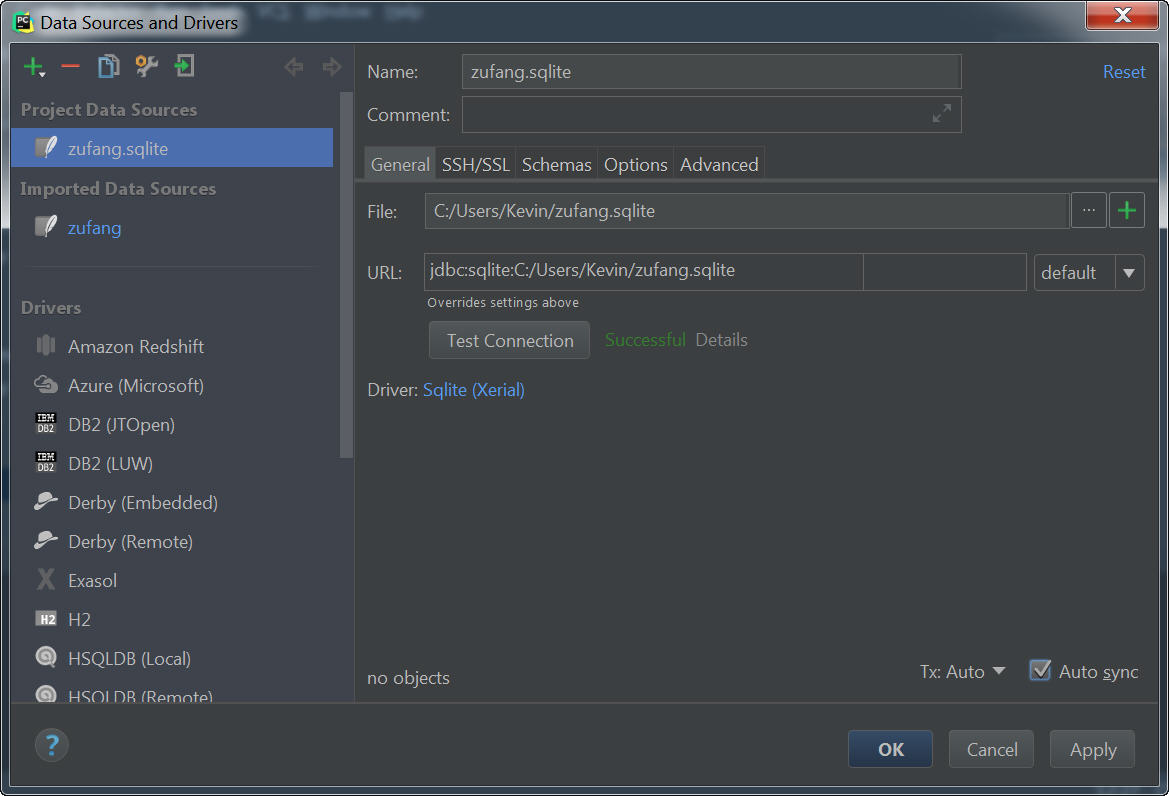
另外,也可以在PYcharm中进行数据库的增、改、删操作,详见这里
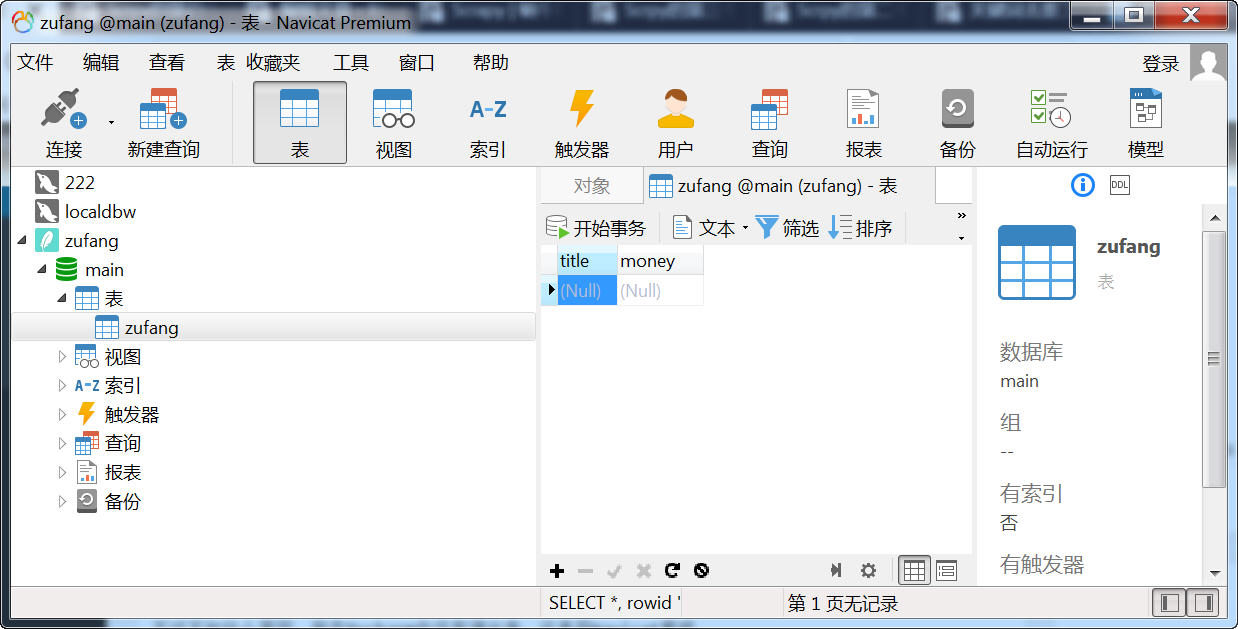
用另一外神器Navicat,也可以看到。
四、修改代码
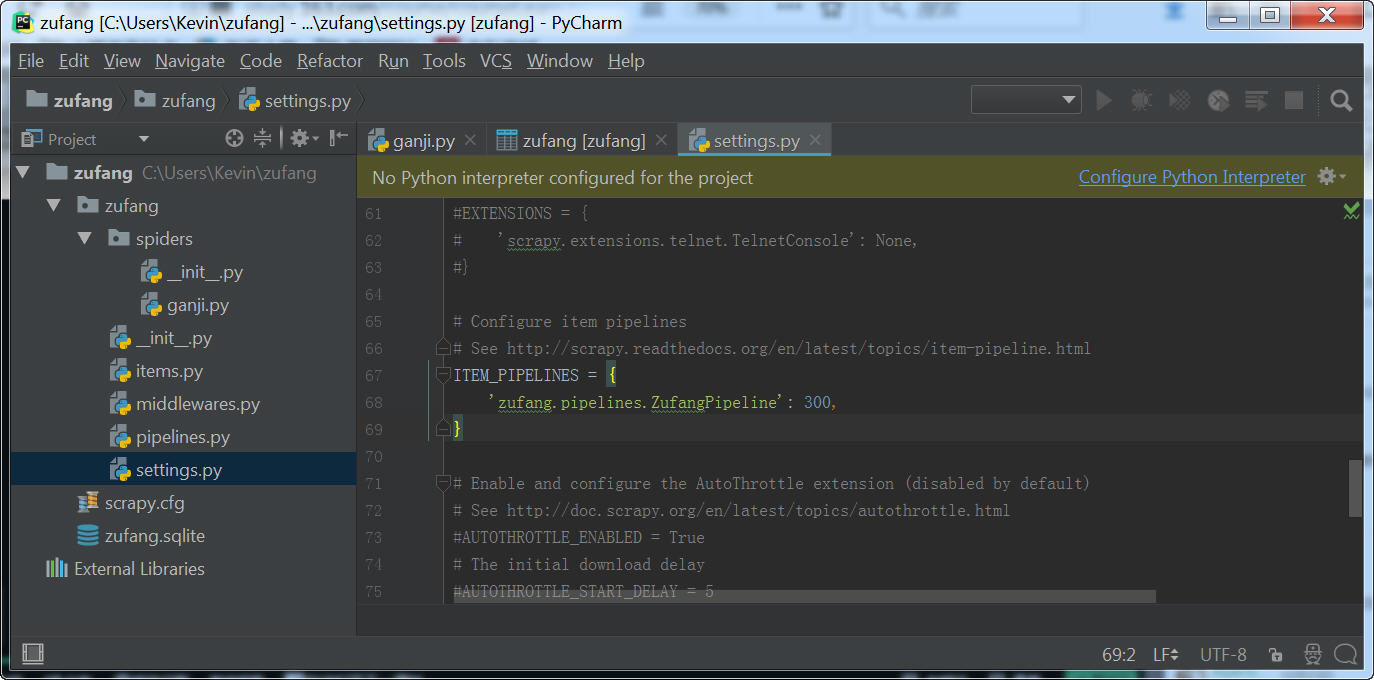
(1)启用项目管道
插入到数据库并不是爬虫文件所做的工作,而是pipelines文件所做的工作,所以要启用pipeline。
在setting.py文件中,找到pipeline所在位置,取消前面的注释即可,后面的300可以设定为1-1000中间的任意数。
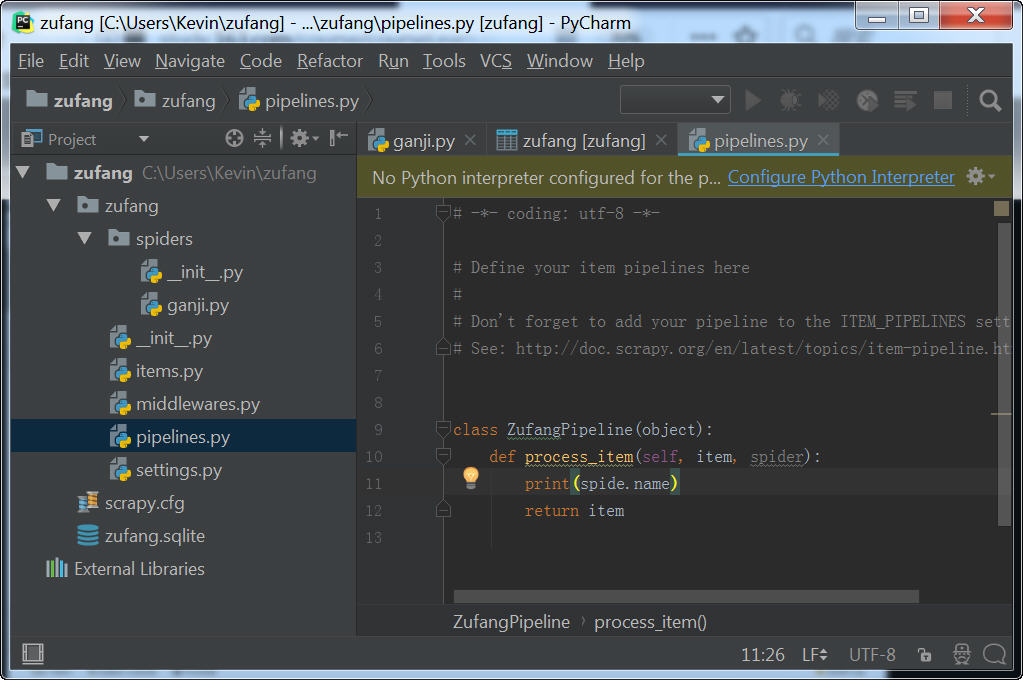
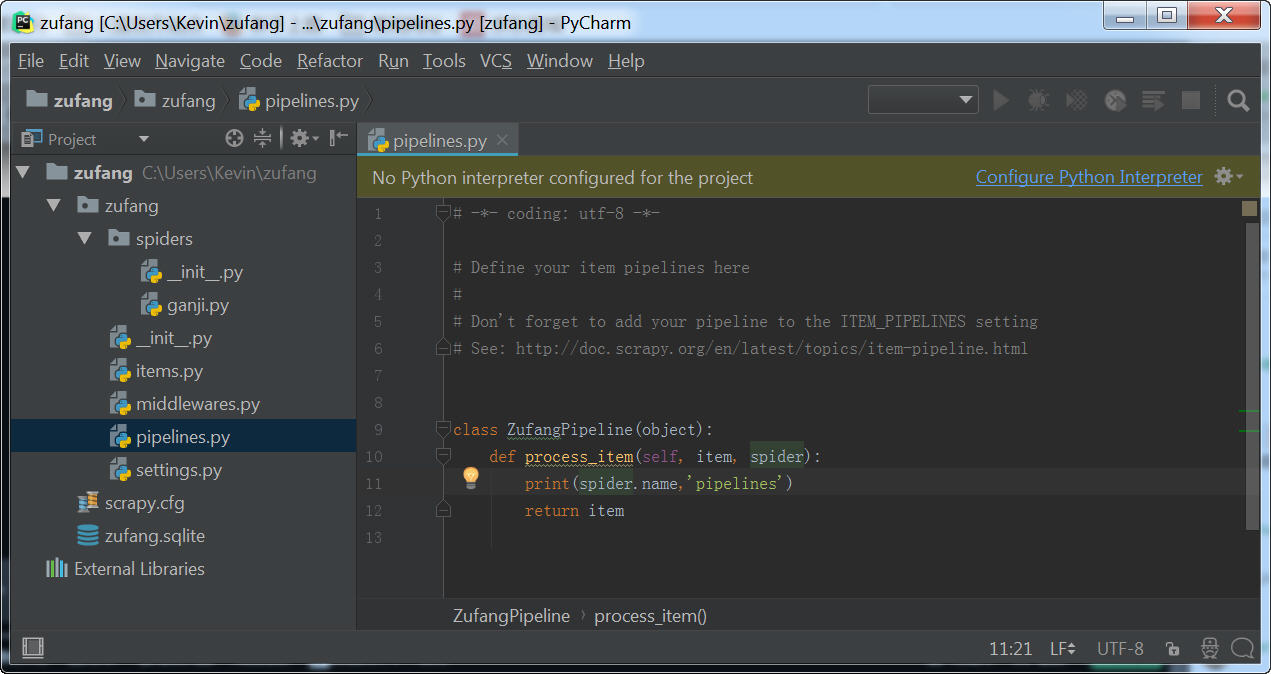
(2)修改pipelines.py文件
添加一行代码,打印出当前是哪一个爬虫将数据传到这里面。
备注:下图截图语法有误,正确的应该是:print(spider.name)
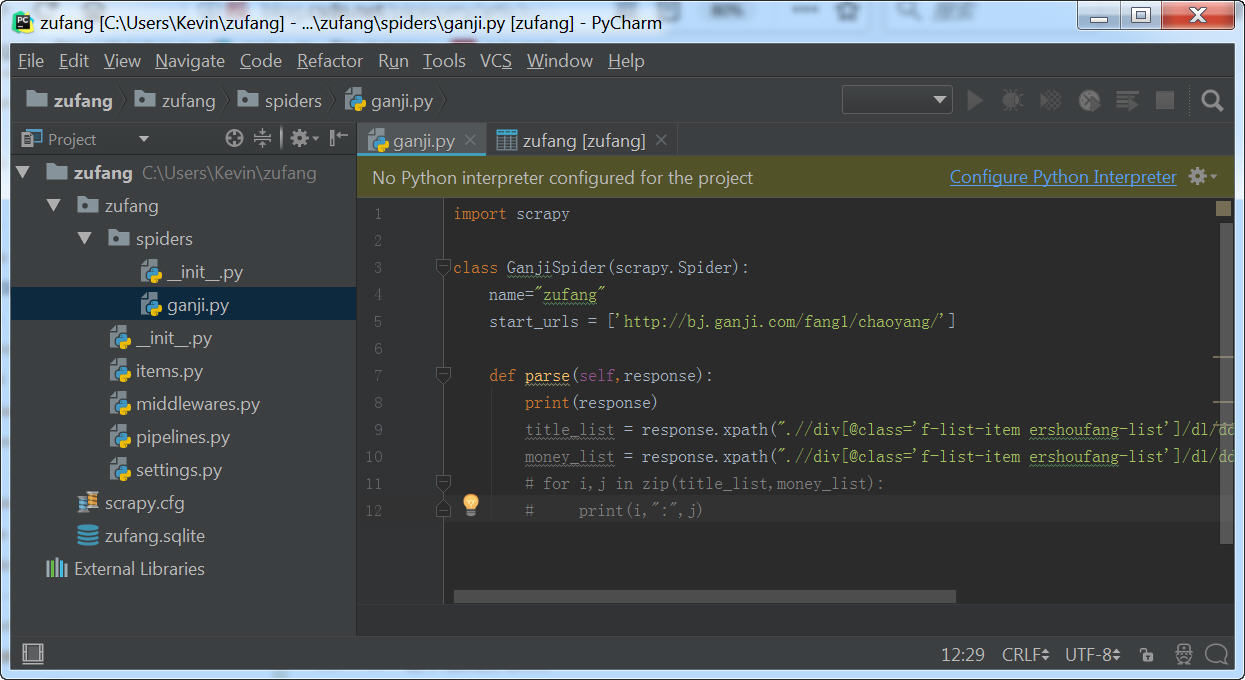
(3)修改ganji.py
按Ctrl+/ 快捷键,将最后两行代码注释掉,在items.py里面定义及输出。
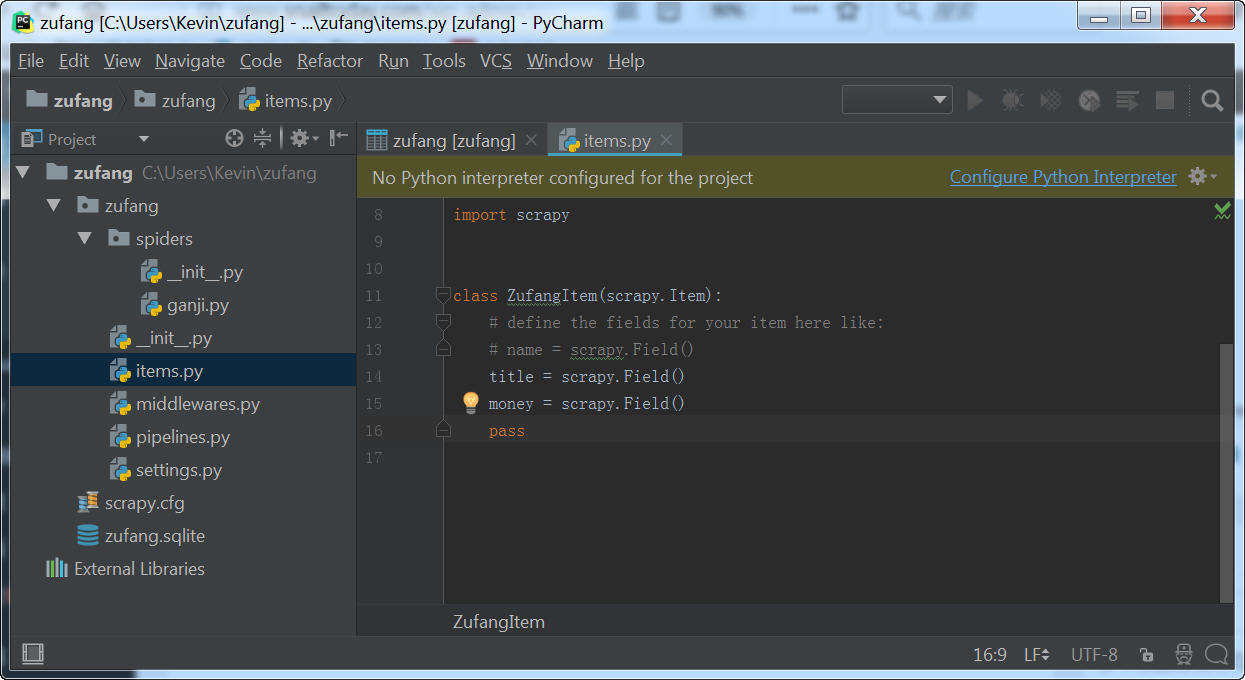
(3)items.py
从爬虫里面将数据传到项目管道文件(pipeline)中,必须通过items里面定义的一个类才能传过去。
(4)ganji.py
导入ZufangItem
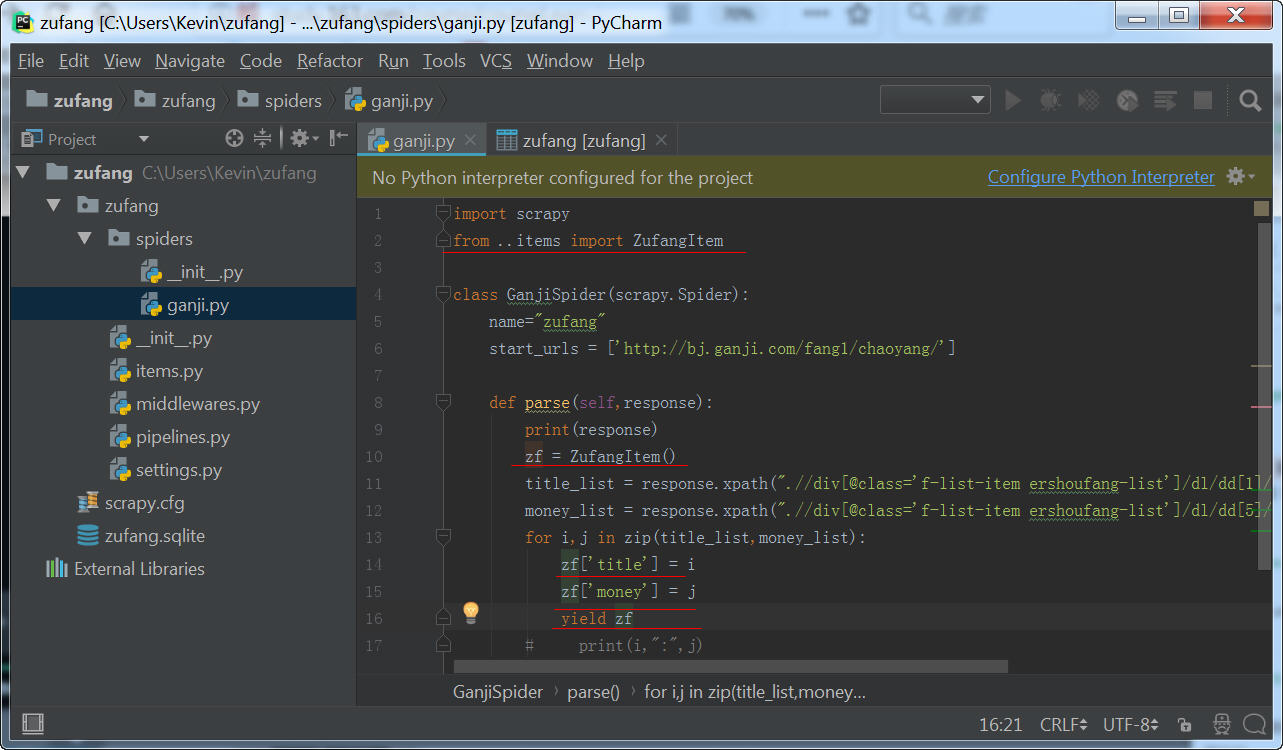
这样的话,一个租房item全部传到了pipeline里面。
(5)修改pipelines.py
我们将其他文件中的输出全部注释掉,只留下pipelines.py有输出信息,并且在里面输出Pipelines。
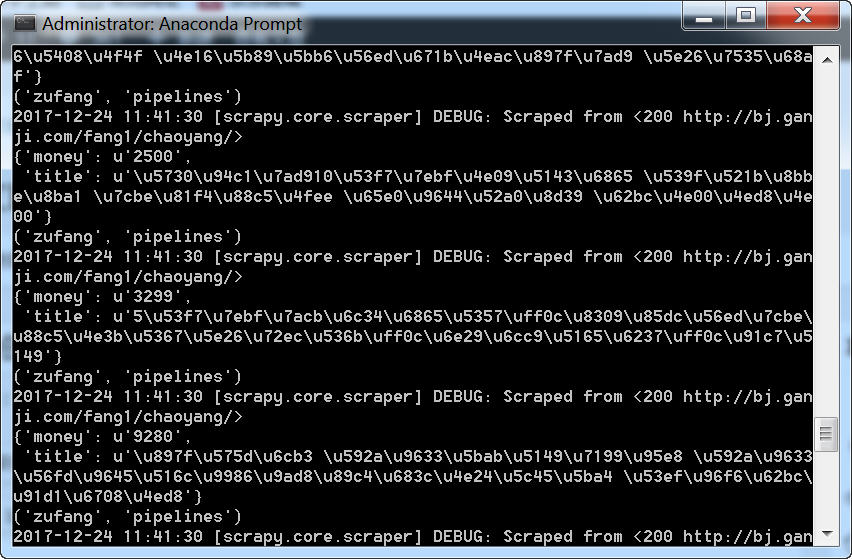
(6)运行爬虫
在终端里面看到的信息,只有在pipelines里面有输出,所以,我们可以确认所有数据已经传到项目管道中来了。
五、插入数据库
爬虫只负责对网页进行分析并获得数据,管道文件负责对数据进行清理并把数据插入到数据库中进行入库。
将pipesline.py的代码修改成
import sqlite3
class ZufangPipeline(object):
def open_spider(self, spider):
self.con = sqlite3.connect("zufang.sqlite")
self.cu = self.con.cursor()
def process_item(self, item, spider):
print(spider.name,'pipelines')
insert_sql = "insert into zufang (title,money) values('{}','{}')".format(item['title'], item['money'])
print(insert_sql) #为了方便调试
self.cu.execute(insert_sql)
self.con.commit()
return item
def spider_close(self, spider):
self.con.close()
六、运行爬虫
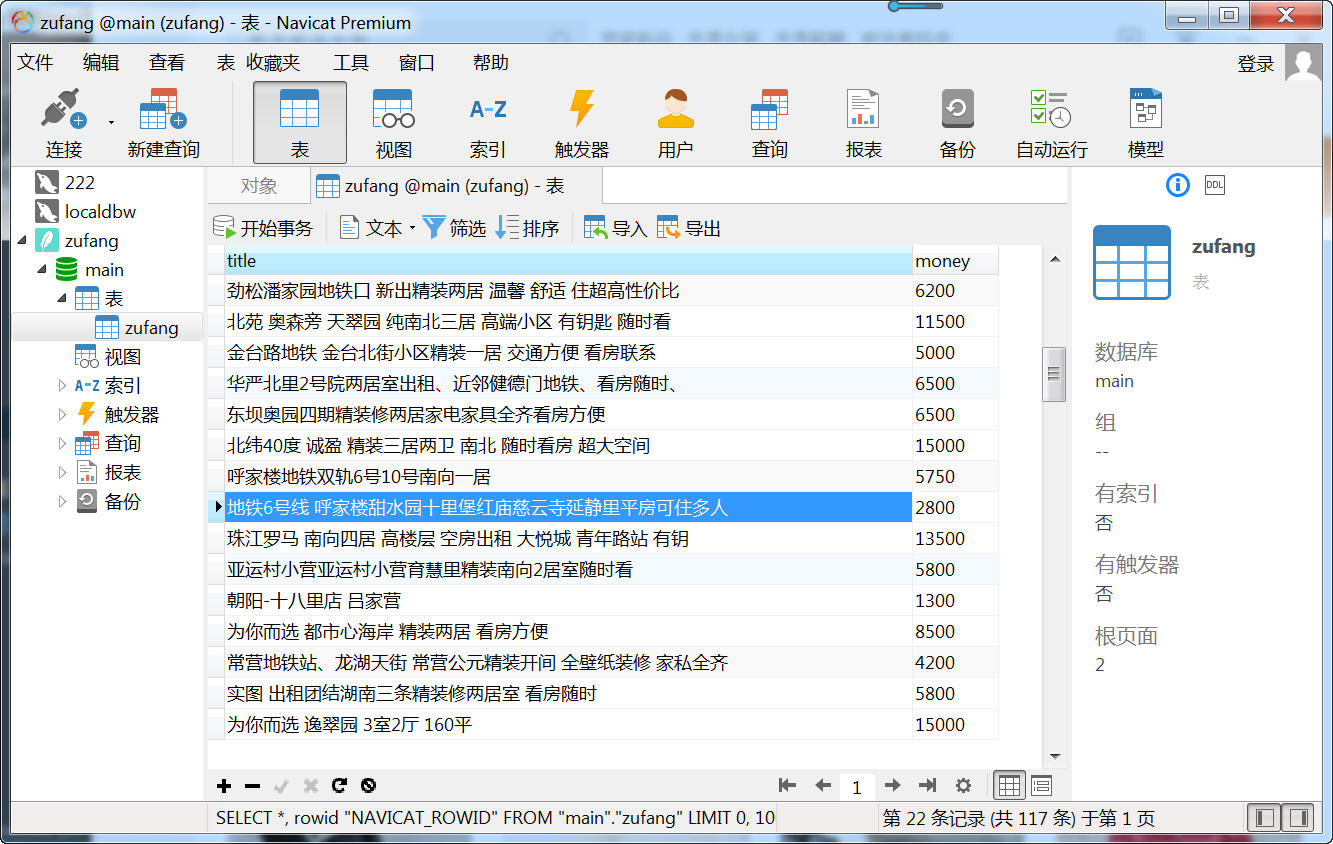
运行zufang爬虫,如果没有出错信息的话,就可以在zufang.sqlite看到采集的数据了。
七、错误解决
在我的电脑上运行以上代码,数据没有插入成功,结果出现了“UnicodeEncodeError: 'ascii' codec can't encode character u'\u6211' in position 0: ordinal not in range(128)”的错误信息。
在pipelines.py文件头加入以下三行代码解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
虽然终端显示仍为乱码。
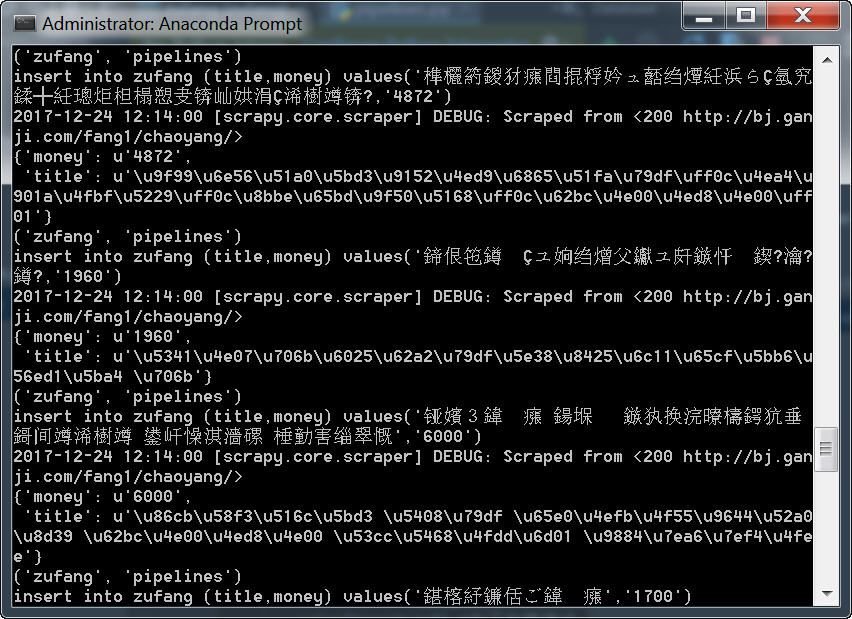
但是终于入库成功了。
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。