

一、安装
(一)创建虚拟环境
virtualenv png08_venv
(二)修改安装参数
将requirements.txt中的Pillow==4.2.1这一行直接改成Pillow,不然安装会报错。
(三)安装
pip install -r requirements.txt
(四)在phpmyadmin新建一个数据库,而且要选择"utf-8 general-ci"
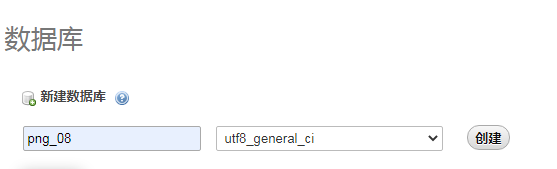
不然会报错:
H:\py_project\png_07\png_07_venv\lib\site-packages\pymysql\cursors.py:166: Warni
ng: (1366, "Incorrect string value: '\\xE7\\x94\\xA8\\xE6\\x88\\xB7' for column
'name' at row 1")
result = self._query(query)
H:\py_project\png_07\png_07_venv\lib\site-packages\pymysql\cursors.py:166: Warni
ng: (1366, "Incorrect string value: '\\xE7\\x94\\xA8\\xE6\\x88\\xB7' for column
'name' at row 2")
result = self._query(query)
H:\py_project\png_07\png_07_venv\lib\site-packages\pymysql\cursors.py:166: Warni
ng: (1366, "Incorrect string value: '\\xE7\\x94\\xA8\\xE6\\x88\\xB7' for column
'name' at row 3")
result = self._query(query)
H:\py_project\png_07\png_07_venv\lib\site-packages\pymysql\cursors.py:166: Warni
ng: (1366, "Incorrect string value: '\\xE6\\x96\\x87\\xE7\\xAB\\xA0' for column
'name' at row 1")
(五)修改数据库配置
首先修改django中的數據庫配置信息,修改settings.py配置信息中的TEST
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
'HOST':'127.0.0.1',
'PORT':'3306',
'NAME':'guest',
'USER':'root',
'PASSWORD':'111111',
}
}
https://www.itdaan.com/tw/37ecff60a10fd50d6ac696a9bbace1e4
(六)修改django文件
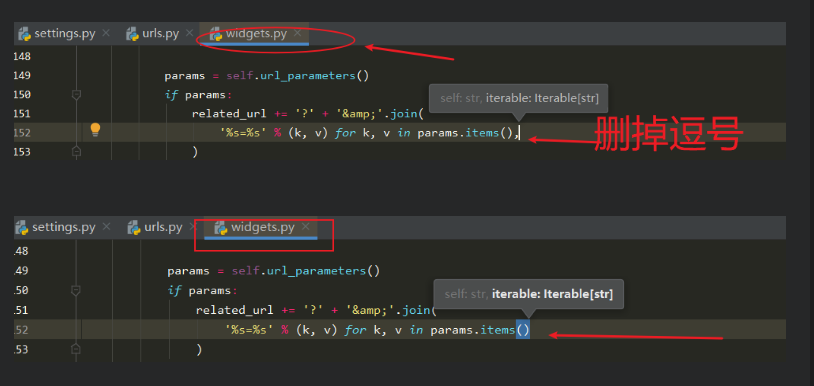
这时执行migrate,会报错:
SyntaxError: Generator expression must be parenthesized, '%s=%s' % (k, v) for k, v in params.it
需要修改下面这个文件:
File "H:\py_project\png_08\png08_venv\lib\site-packages\django\contrib\admin\w
idgets.py", line 152
修改源代码,去掉那个逗号。
(七)安装mysql
pip install pymysql
django项目__inti__.py中添加以下代码
import pymysql pymysql.install_as_MySQLdb()
(八)生成数据库
python manage.py makemigrations python manage.py migrate
(九)生成后台账号,并运行程序员
python manage.py createsuperuser python manage.py runserver
效果预览:
十、后台
地址:http://127.0.0.1:8000/adminx/login/?next=/adminx/
十一、view and class
ListView用来展示一个对象的列表。它只需要一个参数模型名称即可。比如我们希望展示所有文章列表,我们的views.py可以简化为:
from django.views.generic import ListView
from .models import Article
class IndexView(ListView):
model = Article
上述代码等同于:
# 展示所有文章
def index(request):
queryset = Article.objects.all()
return render(request, 'blog/article_list.html', {"article_list": queryset})
十二、slug的处理
直接用正则
import re
result = re.findall(r'\w+', "that's $ very_good_#1")
print('-'.join(result)) # 78za8892HKa2
输出结果是:that-s-very_good_-1
后来发现python有一个的slugify的包。
pip安装,结果用不了,后来到https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml 这里安装就可以用了。
from slugify import slugify txt = "that's $ very_good_#1" r = slugify(txt) print(r)
备注:合适下面的命令来安装
pip install python-slugify
但是输出结果是:that-s-very-good-1,还是有点不满意,不过基本上可以用了。
参考:http://www.voidcn.com/article/p-zybtvlyf-bmd.html
十三、写入数据库
import html
import pymysql
con = pymysql.connect(host='localhost', user='root', password='', database='png_09', charset='utf8')
cursor = con.cursor()
import traceback
title ="大二男生从上海坐公交到北京05"
summary ="近日,上海高校大二学生唐同学从上海坐公交到北京05"
body = "5月13日,“大二男生从上海坐公交到北京”的词条登上热搜。故事的主角,是来自华东理工大学的大二男生唐同学。他从4月29日起坐公交从上海奉贤出发,5月4日抵达了北京路庄,几乎全程坐着公交车完成了这趟1810公里的旅行。5月9日,唐同学在B站发布了一条近16分钟的视频,将自己从出发到结束的所有行程完整展现。第几天,几点到几点,哪一路公交,乘坐多少站,一班多少公里,总里程多少,均进行了详实的记录。视频截图 "
img_link = "/static/blog/img/summary.png"
views = "110"
slug = "post-p3-test5"
author_id = "1"
category_id = "1"
image_download = "https://www.xxx.com/ourpic/u2q8q8w7t4i1o0e6_black-book-clipart-libros-vector-blanco-y-negro/"
image_type = "png"
license_no = "personal_use"
resolution = "1200x1200"
size = "77kb"
# update_date =
def insert_db(title,summary,body,img_link,views,slug,author_id,category_id,image_download,image_type,license_no,resolution,size):
sql ="INSERT INTO blog_article(title,summary,body,img_link,views,slug,author_id,category_id,image_download,image_type,license_no,resolution,size) VALUES ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"%(title,summary,body,img_link,views,slug,author_id,category_id,image_download,image_type,license_no,resolution,size) #最前面的引号要变成双引号,ignore表示忽略重复数据,不过先要设定索引
try:
cursor.execute(sql)
tag_id = cursor.lastrowid
con.commit()
print('tag写入数据库成功!ID为{}'.format(tag_id))
except:
con.rollback()
traceback.print_exc()
print('文章写入数据库失败!')
tag_id = 0
return tag_id
insert_db(title,summary,body,img_link,views,slug,author_id,category_id,image_download,image_type,license_no,resolution,size)
参考:https://github.com/Hopetree/izone/wiki/v1-1.0
十四、关于分页
分页的设置除了在views那里,还有settings.py里面也有:
# 统一分页设置 BASE_PAGE_BY = 10 BASE_ORPHANS = 5 #在最后一页中充许的最少条目数量,默认是0.当最后一页条目数量小于或等于orphans时,这些条目加到本页的上一页中。
参考:https://blog.csdn.net/qq_43381887/article/details/104221227
标签的分页:
要将
<a class="item" href="/?page={{ page_obj.previous_page_number }}">Pre</a>
前面的斜线去掉。
十四、首页
首页的列表内容显示是在blog/tags/article_list.html里面控制的。
十五、搜索
(一)搜索页面的模板
位于izone-1-1.0\templates\search下面的serch.html
(二)与HAYSTACK有关的配置
izone-1-1.0\apps\blog\search_index.py文件。
备注:search_indexes名字不能改
# -*- coding: utf-8 -*-
from haystack import indexes
from .models import Article
class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
views = indexes.IntegerField(model_attr='views')
def get_model(self):
return Article
def index_queryset(self, using=None):
return self.get_model().objects.all()
参考:https://www.cnblogs.com/chichung/p/10017539.html
(三)搜索结果不准确
最开始搜索结果根本不准确,后来执行了一次下面的命令之后,搜索结果才变准确了。
python manage.py rebuild_index
参考:https://blog.csdn.net/qq_37748146/article/details/90723891?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
十六、静态文件
网站部署到服务器上之后,静态文件老是无法加载,折腾了一个星期,最后自己终于搞定了。
原来要在settings.py中将debug设置为True。