一、正则
(一)几个使用正则的实例
1.查找
比如:要从“共200页,到第', '页”里面取出200这个数字,
1 | pagenum=re.findall(r'\d',str) #取到的是一个列表['5', '0', '0'] |
2 | x = soup.find_all('p') #找到所有p标签 |
2.替换
sub三个必选参数:pattern, repl, string,
repl,就是replacement,被替换成的字符串的意思
1 | pagenum=re.sub(r'\D','',str) #取的是500这个数字。即将所有非数字替换成空格 |
2 | replacedStr = re.sub("\d+", "222", inputStr) #将所有数字换成222 |
1 | p1 = '<div>.*?</i> Read More</a></div>' # 这是我们写的正则表达式规则 |
2 | pattern1 = re.compile(p1) # 我们在编译这段正则表达式 |
3 | y = re.sub(pattern1,'',str(x)) |
3.网页解析,使用(.*?)获取内容
5 | html html.decode('gdk') |
10 | req ='<li><a href="(.*?)"> title=".*?">(.*?)</a><li>' |
11 | uls = re.findall(req,html) |
4.多行匹配
2 | req = r'</script>(.*?)<script>' |
4 | req = re.compile(req,re.S) |
5 | chapt_content = re.findall(req,chapt_html) |
5.正则与lambda函数
1 | from bs4 import BeautifulSoup as bs |
6 | html_get = req.get(base_url + '/web/guest/144') |
7 | soup = bs(html_get.text, "html.parser") |
8 | links = [ base_url + link['href'] for link in soup.findAll(lambda tag:tag.name=="a" and '确诊病例' in tag.text) ] |
12 | elements = re.findall('\S某,.*?(?=。)', html.text, re.UNICODE |re.M) |
13 | lists = lists + elements |
14 | print ("->{0} [{1}]".format(link, len(elements))) |
15 | print ("Total: {0}".format(len(lists))) |
6.常用正则
1 | 匹配IP地址的正则表达式 res=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g |
2 | 匹配空行的正则表达式:res=\n[\s| ]*\r |
3 | 匹配HTML标记的正则表达式:res=/<(.*)>.*<\/\1>|<(.*) \/>/ |
4 | 匹配首尾空格的正则表达式:res=(^\s*)|(\s*$) |
5 | 匹配中文字符的正则表达式: res=[\u4e00-\u9fa5] #python中需要转换为unicode |
6 | 匹配双字节字符(包括汉字在内):res=[^\x00-\xff] |
7 | user_phone=r"((?:13[0-9]|14[579]|15[0-3,5-9]|17[0135678]|18[0-9])\d{8})" |
8 | user_name=r""+u"([\u4e00-\u9fa5\·]{2,3})" |
9 | user_id_18=r"([1-9]\d{5}(?:1[9,8]\d{2}|20[0,1]\d)(?:0[1-9]|1[0-2])(?:0[1-9]|1[0-9]|2[0-9]|3[0,1])\d{3}[\dxX])" |
10 | user_id_15=r"([1-9]\d{7}(?:0[1-9]|1[0-2])(?:0[1-9]|1[0-9]|2[0-9]|3[0,1])\d{2}[\dxX])" |
11 | car_id=r""+u"([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})" |
12 | email=r"([a-z_0-9.-]{2,64}@[a-z0-9-]{2,200}\.[a-z]{2,6})" |
13 | address=r""+u"([\u4e00-\u9fa5\·]{6,20})" |
15 | res=ur"[\u4e00-\u9fa5]" |
7.报错:TypeError: expected string or bytes-like object
一般为数据类型不匹配造成的。比如BeautifulSoup里的soup.select()选出来的数据是list列表类型,分别取出列表内的数据,它们的数据类型为,原来Beautiful Soup 将复杂HTML文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:
Tag
NavigableString
BeautifulSoup
Comment
直接对数据用正则表达式,
2 | # says是一个列表,来自says = soup.select('div.status-saying > blockquote') |
3 | say = re.search('(.*?)',say) |
出现错误TypeError: expected string or bytes-like object,这时只要加上say = str(say)就可以了。
8.class 'bs4.element.Tag'
我使用soup.find得到的结果,用type查看是class 'bs4.element.Tag',需要将其转换为str类型,即加上str即可。
参考:https://www.jianshu.com/p/d67a3858728c
9.报错:requests.exceptions.SSLError: HTTPSConnectionPool
(1)加headers
(2)上faqi,国外ip
(二)正则规则
1.正则的规则1


2.正则规则2
1 | []:指定一个字符集,'[abc\s\d]'中,a,b,c任意一个满足便可以。 |
2 | {}:重复,a{8}=aaaaaaaa;b{1,3}:重复1-3次。 |
3 | ^:匹配行首,'[^abc]'中,除了a,b,c,其他的都可以;'^hello'表示行首是hello的字符串。 |
4 | $:匹配行尾,'boy$'表示行尾是boy的字符串。 |
9 | *:指定前一个字符匹配0次或多次。'ab*',可以匹配a,ab,abb,abbbb等。 |
11 | ?:指定前一个字符匹配0次或1次,加载重复后面可以最小匹配。 |
12 | .:表示任意字符(换行符\n除外re.DOTALL可以匹配所有字符串,包括换行;re.compile(r".*",re.DOTALL) |
13 | (?i):在正则表达式前面加上这个,便可以忽略大小写;如:res=r"(?i)[abc]" |
14 | (asp|php|jsp):表示或者,跟[abc]的区别在于它是匹配一个字符串,而[]只是单个字符。 |
15 | r'((?[\d]*){2,3})':在内括号前加上?:,结果只匹配外面括号的内容。 |
18 | \d{4}年\d{2}月\d{2}日匹配是个数字(2019年07月15日) 。 |
3.Python中使用正则
4 | content="abcd12345678abcd" #待匹配的内容 |
6 | a=re.search(res,content) |
11 | p_tel=re.compile(res) 将正则表达式编译,提高运行速度。 |
12 | p_tel.findall(content) 找到RE匹配的所有子串,并作为列表返回。 |
13 | p_tel.match(content) 决定RE是否在字符串刚开始的位置匹配。 |
14 | p_tel.search(content) 扫描字符串,找到这个RE匹配的位置。 |
15 | p_tel.group(num=0) 返回全部匹配对象。(或指定编号是num的子组) |
16 | p_tel.sub(pattern,string) 对正则表达式中所有匹配string的用pattern替换。 |
17 | p_tel.split(pattern,string) 根据正则表达式pattern中的分隔符把字符string分隔为一个列表。 |
贪婪模式
需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
例子:
1 | >>> re.match(r'^(\d+)(0*)$', '123400').groups() |
说明:由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:'
1 | >>> re.match(r'^(\d+?)(0*)$', '123400').groups() |
二、SEO中的使用
2 | title = re.search(r'name="description" content="(.*?)"', html).group(1) |
gogo闯的代码
3 | a = re.sub(r'<script.*?>([\s\S]*?)<\/script>','',text) |
5 | b = re.sub(r'<style.*?>([\s\S]*?)</style>','',a) |
7 | c = re.sub(r'{[\s\S]*}','',b) |
9 | d = re.sub(r'<(?!p|img|/p)[^<>]*?>','',c).strip() #将除p和img之外的标签清空,且去除正文开头结尾的换行,并把单引号换成双引号 |
11 | e = re.sub(r'<p[^>]*?>','<p>',d) #格式化p标签 |
21 | results=re.compile(r'http://[a-zA-Z0-9.?/&=:]*',re.S) |
对采集的网页进行处理:
1 | # 将除p和img之外的标签清空,且去除正文开头结尾的换行,亲测可用 |
2 | a = re.sub(r'<(?!p|img|/p)[^<>]*?>','',html).strip() |
4 | #对采集到的网页进行处理,将p标签内其他标签去掉 |
5 | content = soup.find('div', {'class': 'text parbase section'}).find_all('p') |
8 | i = re.sub(r'<(?!p|/p)[^<>]*?>','',str(i)) |
12 | # 删除p标签属性,比如<p class="xx">这样的。亲测可用。 |
13 | b = re.sub(r'<p[^>]*?>','<p>',a) |
14 | newcontent = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower() |
17 | re.sub(r'<[^>]*?>','',row[1]).strip() |
19 | new_html = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower() |
24 | text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent) |
25 | text2 = re.sub('<[^>]*?>','',text) |
26 | words_number = len(text2) |
找到P段落,替换一些杂乱字符为空格([^>]表示不是“>”的字符,*表示重复零次或更多次)
1 | for line in re.findall(r'<[p|P][^>]*?>(.*?)</[p|P]>',content): |
2 | line = re.sub(r'<[^>]*?>|&[^:]*?;','',line).strip() |
?涉及到贪婪模式
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)
正则中的r'\b'
r'\b', 如果前面加r, 那么解释器不会进行转义,\b 解释为正则表达式模式中的字符串边界。

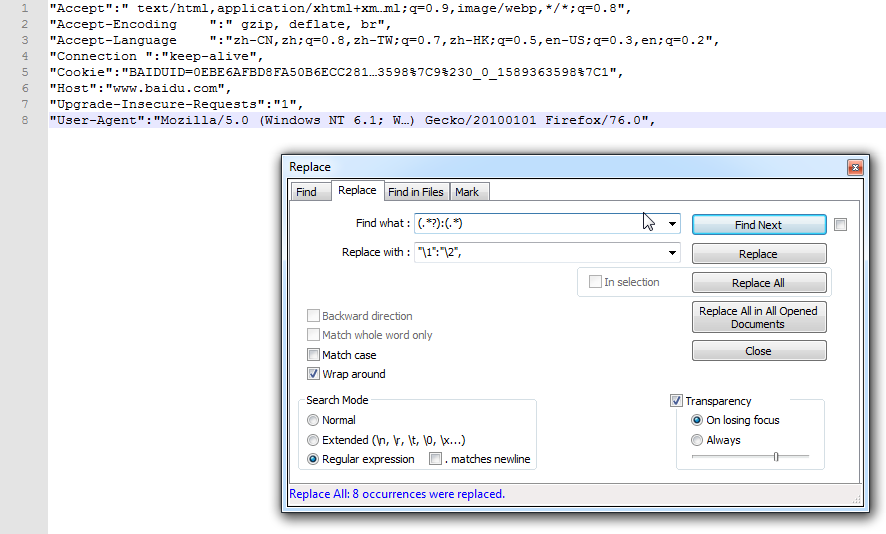
使用Re生成请求头。
searchmode要选正则。
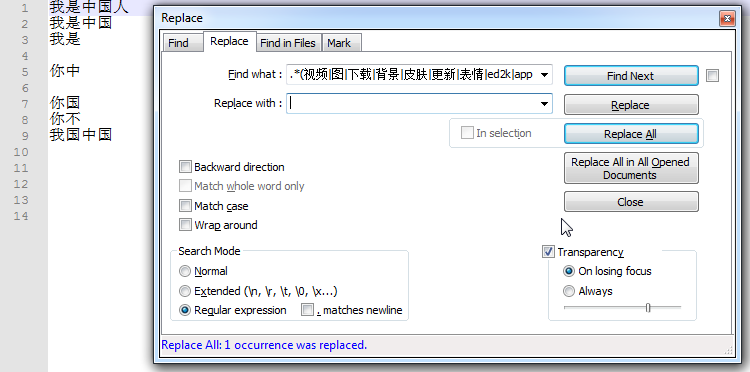
8.对关键词进行处理
意思就是,只要关键词里面包含上面的这些词(用竖线分隔)的其中一个,那么就会被匹配到。那么我们就可以把包含这些我们不想要的关键词给快速的找出来啦。
然后放到vscode里面去,将它们替换为空就好了
1 | .*(视频|图|下载|背景|皮肤|更新|表情|ed2k|app|mp4|mp3).* |
注意,后面有可能要加/n
参考:https://mp.weixin.qq.com/s?__biz=MzU1NTIyMjY1MQ==&mid=2247484260&idx=1&sn=b94ab60e8f019a6493bda9969af95e49&chksm=fbd6d070cca15966ed5b18eccdbdd967e1b2deda50f08080412870d2bed4ad078d936da370dd&mpshare=1&scene=23&srcid=0828kqtqfW5uW8f3gbKOLGOY&sharer_sharetime=1598585459445&sharer_shareid=a48a49981d67dd6148580fa5ee9fb10a#rd
三、BeautifulSoup与正则
(一).我们常用到的方法
1.匹配
- 提取标签文本:soup.{标签名}.get_text()
- 提取包含某属性值的标签文本:soup.find("{标签}", {属性}="{属性值}").get_text()
- 匹配多项,以list形式返回:soup.find_all,比如soup.find_all('p')就是查找所有p标签。
- 配合正则:soup.find("{标签}", {属性}=re.compile("{正则表达式})").get_text()
比如,查找div class=tab_content的内容
1 | x = soup.find('div', {'class': 'tab_content'}) |
如果div class=tab_content下面有p,ul,li等标签,如果要取到所有文字,则用:
1 | x = soup.find('div', {'class': 'tab_content'}).get_text() |
2.多次查找:
1 | content = soup.find('div', {'class': 'text parbase section'}).find_all('p') #得到的是一个列表,一个p一个列表 |
另一个:
1 | content = soup.find('div', {'class': 'text parbase section'}) #也是得到一个列表 |
参考:http://cn.voidcc.com/question/p-brdgwdfi-kt.html
http://www.360doc.com/content/17/0306/21/1489589_634533042.shtml
(二)实例
1.实例一 匹配p 下面的ka=click
3 | soup = BeautifulSoup(html2) |
4 | soup.find_all("p",ka=re.compile(r'click')) |
2.实例二 bs+代理+正则
2 | from bs4 import BeautifulSoup |
7 | html = requests.get(url, timeout=30) |
8 | ip = html.content.strip() |
9 | return bytes.decode(ip) |
11 | proxy_ip = get_http_ip() |
13 | "http": "http://{ip}".format(ip=proxy_ip), |
14 | "https": "http://{ip}".format(ip=proxy_ip), |
19 | html = requests.get(url,proxies=proxies).text |
20 | print("当前正在使用的代理为{}".format(proxies)) |
21 | soup = BeautifulSoup(html,'html.parser') |
22 | x = soup.find('div', {'class': 'tab_content'}) |
3.实例三 BeautifulSoup基本用法
1 | from urllib.request import urlopen,HTTPError |
2 | from bs4 import BeautifulSoup |
5 | url = input("which page would you like to check?:") |
6 | keyword = input("what is your seo keyword?") |
8 | keyword = keyword.casefold() |
15 | data = BeautifulSoup(html,"html.parser") |
17 | def seo_title(keyword,data): |
18 | if keyword in data.title.text.casefold(): |
24 | print(seo_title(keyword,data)) |
参考:
https://www.youtube.com/watch?v=IhLhARwStpk
4.小知识
result=soup.find('div', {'class': 'article-content'})的结果是,如果要与其他文字拼结,需要str(result)再拼接。
(四)常见问题
1.结果是乱码如何解决?
1 | res = requests.get(url,headers = headers) |
2 | res.encoding = 'gb18030' |
3 | soup = BeautifulSoup(res.text,'html.parser') |

