

一、这是发送手机验证码的模板:
import requests
import json
class YunPian(object):
def __init__(self, api_key):
self.api_key = api_key
self.single_send_url = "https://sms.yunpian.com/v2/"
def send_sms(self, code, mobile):
params = {
"apikey": self.api_key,
"mobile": mobile,
"text": "您的验证码是{code},如非本人操作,请忽略本信息。".format(code = code)
}
response = requests.post(self.single_send_url,data=params)
re_dict = json.loads(response.text)
print(re_dict)
if __name__ == "__main__":
yun_pian = YunPian("xxxx")
yun_pian.send_sms("2007","18782902356")
这里又有一个坑,要留意,就是response = requests.post(self.single_send_url,data=params)后面的参数要注意,如果是用的get方法,后面应该要用params=XXX这样的形式,比如params=payload。
备注:
在这里有用到。

二、网页编码
1.编码
import requests
html = requests.get('https://www.baidu.com')
html.encoding = 'utf-8'
print (html.text)
2.requests自动识别编码
response = requests.get("http://www.x.com")
#自动识别解码
response.encoding = response.apparent_encoding
3.request乱码
使用“html.text.encode('utf-8')”也打印不出结果。
乱码的解决方案
其实前面3行就可以了。
四、requests的返回
import requests
response = requests.get("https://www.baidu.com", data=None, timeout=10)
# #打印出服务器响应的header信息
# print("打印出服务器响应的header信息:",response.headers)
# #打印出服务器响应的状态码,结果为<Response [200]>
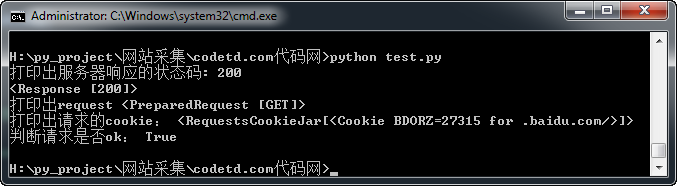
print("打印出服务器响应的状态码:",response.status_code)
print(response)
print("打印出request",response.request)
print("打印出请求的cookie:",response.cookies)
print("判断请求是否ok:",response.ok)
五、request.get
def get_url_content(self,url, max_try_number=5):
#封装的requests.get
try_num = 0
while True:
try:
return requests.get(url, timeout=5)
except Exception as http_err:
print(url, "抓取报错", http_err)
try_num += 1
if try_num >= max_try_number:
print("尝试失败次数过多,放弃尝试")
return None
如何处理request返回的报错信息?
from bs4 import BeautifulSoup
url = '<div class="caller_ref">这是div</div> <a href="/tomasi/cardio/vgh/SPsdeGBHH">超链接</a>'
soup = BeautifulSoup(url,'html.parser')
print("soup的长度是:{}".format(len(soup)))
if soup.title is None:
print("没有title,title is None")
content = soup.find('div', {'class': 'caller_ref1'})
if content is None:
print("没有找到div的值,div返回None")
soup的长度是:3
没有title,title is None
没有找到div的值,div返回None
所以,用len可以判断soup(不能用None),不过即使soup为空白,程序也不会报错。
用none可以判断title,content返回是否为空。
六、添加代理
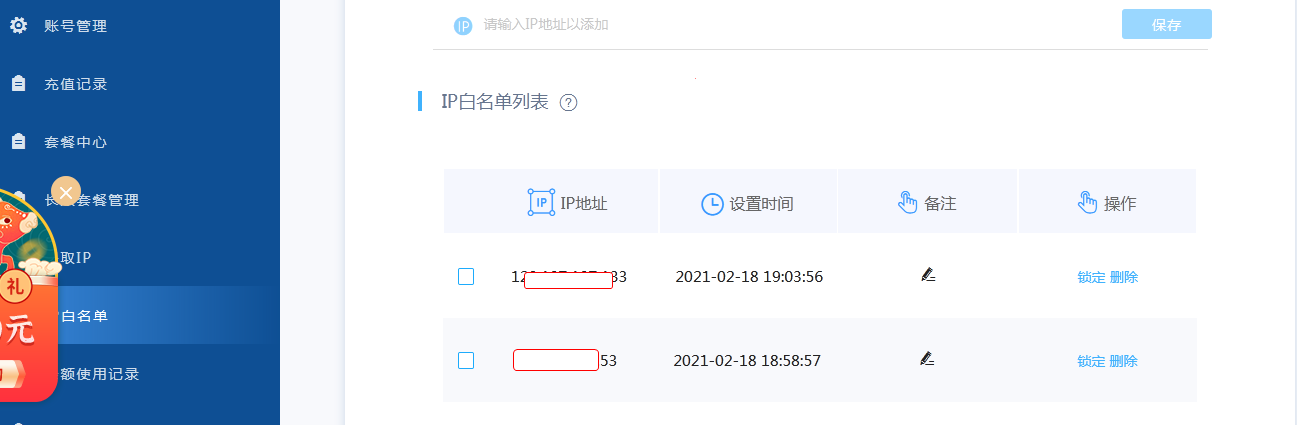
1.需要在http://h.zhimaruanjian.com/getapi/ 的白名单添加本机ip。u:138 Ps:F14
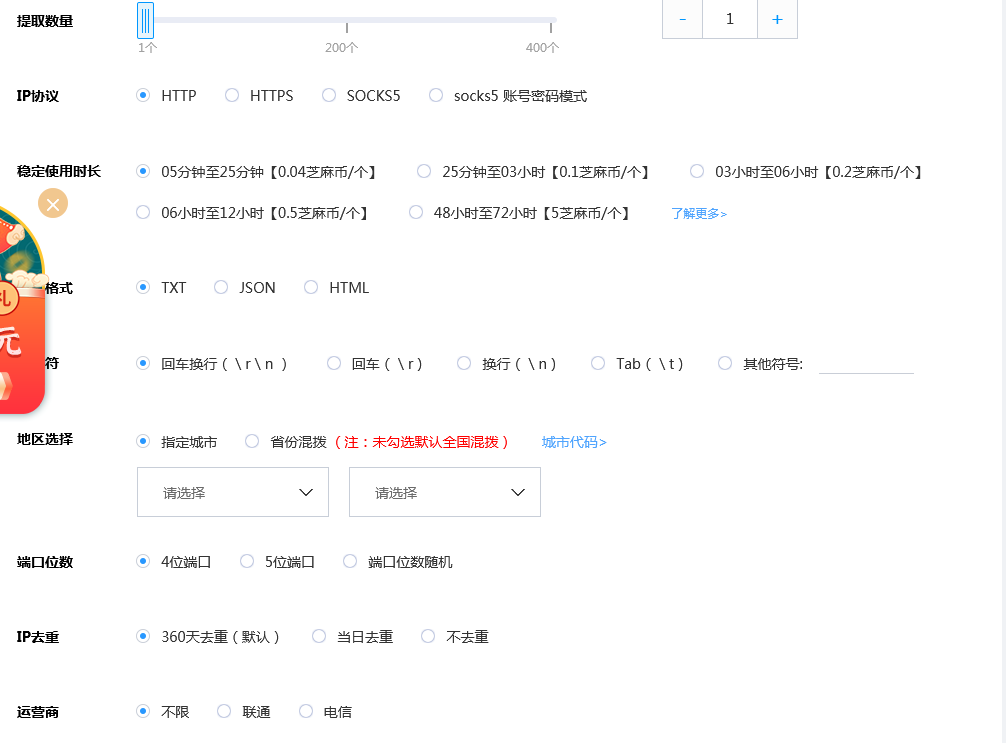
2.相关参数
获取数量选1个。
3.获取代理ip的代码
另外,发现采集国外网站的时候,用自己的ip采集很慢,有时采不到,用代理IP反而快很多。
import requests
import json
# 添加http代理,芝麻代理为例
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '',
'DNT': '1',
'Host': 'www.baidu.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
# 获取代理
def get_http_ip():
url = "http://webapi.http.zhimacangku.com/getip?num=1&type=1&pro=&city=0&yys=0&port=11&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions="
html = requests.get(url, timeout=30)
ip = html.content.strip()
return bytes.decode(ip)
# def get_http_ip(num):
# #使用json的方式取得代理ip
# url= "http://webapi.http.zhimacangku.com/getip?num={}&type=2&pro=&city=0&yys=0&port=1&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions=".format(num)
# html = requests.get(url, timeout=30).text
# json_str = json.loads(html).get('data')
# print(json_str)
proxy_ip = get_http_ip()
proxies = {
"http": "http://{ip}".format(ip=proxy_ip),
"https": "http://{ip}".format(ip=proxy_ip),
}
import requests
html = requests.get('https://www.baidu.com/baidu?tn=dealio_dg&wd=ip', headers=headers, proxies=proxies)
html.encoding = 'utf-8'
content = html.text
import re
ip = re.search(r'class="c-gap-right">本机IP: (.*?)</span>',content)
ip.group(1)
print(ip.group(1))
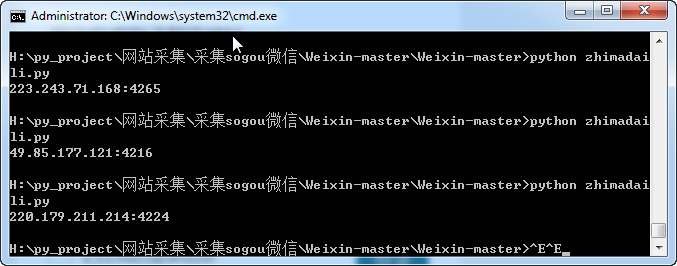
3.效果展示
4.代理池方案
https://blog.csdn.net/qq_37978800/article/details/108182356
七、采集sogou
(一)效果
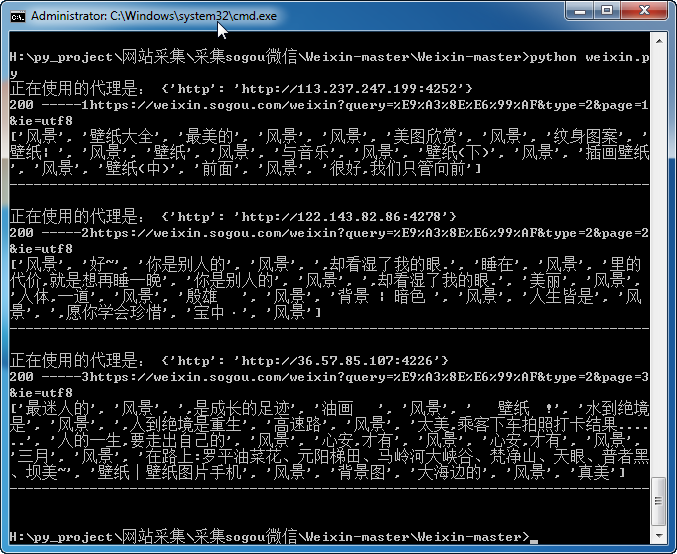
(二)代码
发现加了cookie之后,不需要换IP,采集100页列表页都没有问题。
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import random
import time
headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection":"keep-alive",
"Cookie":"IPLOC=CN4401; SUID=3D88E578302EA00A5EE0A5C700091A7A; CXID=2D2E573D28DBF81F0D5EE82AE194B591; wuid=AAFfVMjnMQAAAAqHDEAx3wAAkwA=; ssuid=4566914326; usid=MQ7Cat9I6sYTA4pv; SNUID=BCA801FC898D3212BEC05BC4892BFA83; SUV=00323ADCDF4A72625F8983AF6ABFA771; FREQUENCY=1602847663829_2; front_screen_resolution=1920*1080; front_screen_dpi=1; sw_uuid=1992113152; ad=wkllllllll2k46ovlllllplWvPwlllllWnQyZyllll9lllllxklll5@@@@@@@@@@; ABTEST=0|1613645893|v1; weixinIndexVisited=1; ld=nkllllllll2kaum2lllllplmziwlllllNYkP2yllllwlll ppinfo=fa4414ad0d; passport=5|1613732661|1614942261|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo1OkJvd2VufGNydDoxMDoxNjEzNzMyNjYxfHJlZm5pY2s6NTpCb3dlbnx1c2VyaWQ6NDQ6bzl0Mmx1Smo1YlMtYk9FRVFMblJMbmxiV3JWMEB3ZWl4aW4uc29odS5jb218|f003b0d15e|JeJkSzFeHtPrilwydblkqBT-ATqXzrachzaryN0RBTvCHeRXs03-K4fxZ1wfTRU027D4KSjaaG6Su6s2zp9AAjpjKwloLvQWBr3lUWVleKg8RszyfMm5Zpc6HqBQX7GfNyFl-p3KXcKdzNF3HHLxU2HJWnXed7AWY6i-TtbGvm8; sgid=05-49569309-AWAvmzW7J4aNYZkPO1K8yA8; ppmdig=1613732663000000b8e1c27bc97c631f915fcdca3f8f2c32",
"Host":"weixin.sogou.com",
"Referer":"https://weixin.sogou.com",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0",
}
def get_proxy():
url = "http://webapi.http.zhimacangku.com/getip?num=1&type=1&pro=&city=0&yys=0&port=1&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions="
try:
response = requests.get(url, timeout=30)
if response.status_code == 200:
ip = response.content.strip()
return bytes.decode(ip)
except ConnectionError:
return None
url2 = "https://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=%d"+"&ie=utf8" ##定义通用翻页url
for pg in range(1,4):
new_url = "https://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page={}".format(pg)+"&ie=utf8"
# print(new_url)
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
print("正在使用的代理是:",proxies)
html2 = requests.get(url=new_url,headers=headers,proxies=proxies)
print(html2.status_code,"-----"+str(pg)+new_url)
tree2 = etree.HTML(html2.text)
title = tree2.xpath("//div[@class='txt-box']/h3/a//text()")
print(title)
# nr = tree2.xpath("//div[@class='txt-box']/p//text()")
# print(nr)
print("-"*80)
time.sleep(1) #因为代理网站1秒只能获取一个IP,所以这里需要暂停1秒。