

一、Django中单独使用Models
我们之前都是将项目拉起来再使用Django Model,许多同学不知道其实django model是可以独立出来使用的,下面我们来看看如何将django model独立出来使用。
在django的项目中新建一个DB_tools的文件夹,再在文件夹中建立一个import_da.py的文件,首先加入以下代码。
代码:
import sys
import os
script_dir = os.path.split(os.path.realpath(__file__))[0] # 获取脚本所在的目录
prj_dir = os.path.dirname(script_dir) # 获取其上级目录,及django项目所在的目录。
sys.path.append(prj_dir) # 在python系统路径中加入上一步得到的目录。
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "cpsite.settings") # 设置DJANGO_SETTINGS_MODULE变量。cpsite即settings.py所在的文件夹名称
import django
django.setup()
执行一下有没有出错信息,没有的话就表示OK了。
我是参照这里的代码弄的。
二、数据入库
折腾中自己解决的问题如下:
1、如何调用其他文件中的class,如果是同目录,直接from 文件名 import 类名 就可以了。
2、字典中某个键不存在的情况下,如何解决? (通过for循环,然后if "xx" in 就可以了)
3、从API中取数,有时也会存在数据不全的情况,这里要参考出错信息,看看是不是数据源的问题,而不是一直找自己代码的原因。
至此,除了商品详情中的描述内容外,其他的需要取的数据都已经取到了。
代码如下:
import sys
import os
import requests
import json
import time
script_dir = os.path.split(os.path.realpath(__file__))[0] # 获取脚本所在的目录
prj_dir = os.path.dirname(script_dir) # 获取其上级目录,及django项目所在的目录。
sys.path.append(prj_dir) # 在python系统路径中加入上一步得到的目录。
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "cpsite.settings")
import django
django.setup()
from coupon.models import Goods
unionId = "000000" #请输入你的联盟ID
"""
获得商品优惠券二合一转链的类
"""
class Get_coupon_link(object):
def __init__(self, unionId):
self.unionId = unionId
self.start_url = "https://jd.xxx.cn/union/getCouponCodeByUnionId"
def get_link(self, couponUrl,materialIds):
payload = {
"unionId":self.unionId,
"couponUrl": couponUrl,
"materialIds": materialIds
}
response = requests.get(self.start_url,params=payload)
re_dict = json.loads(response.text)
print(re_dict['msg'])
print(re_dict['data'][0]['couponCode'])
return re_dict
"""
通过优惠券商品查询获得最终的数据
"""
def get_coupon_product():
response = requests.get("https://jd.xxx.cn/union/queryCouponGoods?pageIndex=0&pageSize=10")
re_dict = json.loads(response.text)
goods_list = re_dict['data']['goodsList']
for single_coupon_product in goods_list:
if "couponList" in single_coupon_product:
newgoods = Goods()
get_coupon_product_link = Get_coupon_link(unionId)
return_coupon = get_coupon_product_link.get_link(couponUrl="http:"+single_coupon_product['couponList'][0]['link'],materialIds=single_coupon_product['skuId'])
if return_coupon["code"] == 1:
if len(return_coupon['data'][0]['couponCode']) == 0:
newgoods.url = return_coupon['data'][0]['couponUrl']
else:
newgoods.url = return_coupon['data'][0]['couponCode']
else:
print(return_coupon['msg'])
newgoods.name = single_coupon_product['skuName']
newgoods.skuid = single_coupon_product['skuId']
newgoods.imageurl = "http://img14.360buyimg.com/n1/"+single_coupon_product['imageurl']
newgoods.recommand = single_coupon_product['skuName']
newgoods.sale_price = single_coupon_product['pcPrice']
newgoods.coupon_price = single_coupon_product['pcPrice']-single_coupon_product['couponList'][0]['discount']
newgoods.coupon_amount = single_coupon_product['couponList'][0]['discount']
newgoods.detail = single_coupon_product['skuName']+"http://img14.360buyimg.com/n1/"+single_coupon_product['imageurl']
newgoods.save()
time.sleep(0.5)
else:
continue
if __name__ == "__main__":
get_coupon_product()
小提示:
1、要注意“from coupon.models import Goods”这段代码的放置位置。
2、如果出现如下的错误:
RuntimeWarning: DateTimeField Goods.add_time received a naive datetime (2018-07-27 22:11:37.782982) while time zone support is active. RuntimeWarning)
这时只需要打开settings.py文件 ,将其中的USE_TZ = True改成USE_TZ = False即可。
下面是修改前后,写入数据库的对比,几乎是同时添加的,但是相差了8小时:
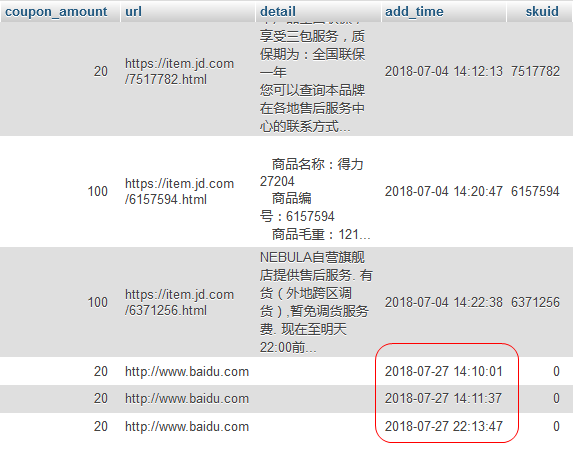
Updated on Aug-11-2019:
要注意入库时的异常处理,以及字段的unique=true的设置:
for i in range(0,8):
newQuestion = Question()
newQuestion.qid = questions[i]['id']
newQuestion.title = questions[i]['title']
newQuestion.content = questions[i]['content']
#生成随机数
userid = random.randint(14,617)
newQuestion.user_id = userid
try:
newQuestion.save()
except Exception as e:
print("******发生导常:{}".format(e))
continue
questionWebId = questions[i]['id']
answer = getAnser(questionWebId)
newAnser = Answer()
newAnser.content = answer
newAnser.question_id =newQuestion.id
#生成随机数
userid = random.randint(14,617)
newAnser.user_id = userid
try:
newAnser.save()
except Exception as e:
print("******发生导常:{}".format(e))
continue
print("-----已经完成第{}条数据的采集!-----".format(i))
print("已经完成第{}页数据的采集!".format(n))
print("*"*80)
三、京东商品评论
测试代码如下:
import requests
import json
def craw_comment(skuid):
url = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv56668&productId={id}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1".format(id=skuid)
html = requests.get(url)
html = html.text.replace('fetchJSON_comment98vv56668(', '')
html = html.replace(');', '')
re_dict = json.loads(html)
# print(re_dict['comments'][0]['content'])
for i in re_dict['comments']:
productName = i['referenceName']
commentTime = i['creationTime']
content = i['content']
userLevel = i['userLevelName']
userClientShow = i['userClientShow']
# 输出商品评论关键信息
print("商品全名:{}".format(productName))
print("用户评论时间:{}".format(commentTime))
print("用户评论内容:{}".format(content))
print("用户等级:{}".format(userLevel))
print("评论来源:{}".format(userClientShow))
print("-----------------------------")
craw_comment(3754169)
小提示:
开始取到的结果并不是标准的json格式,需要将多余的字符替换掉,直接取{}里面的内容,然后复制到在线json解析网站上,就可以以格式化的方式显示了。
运行结果
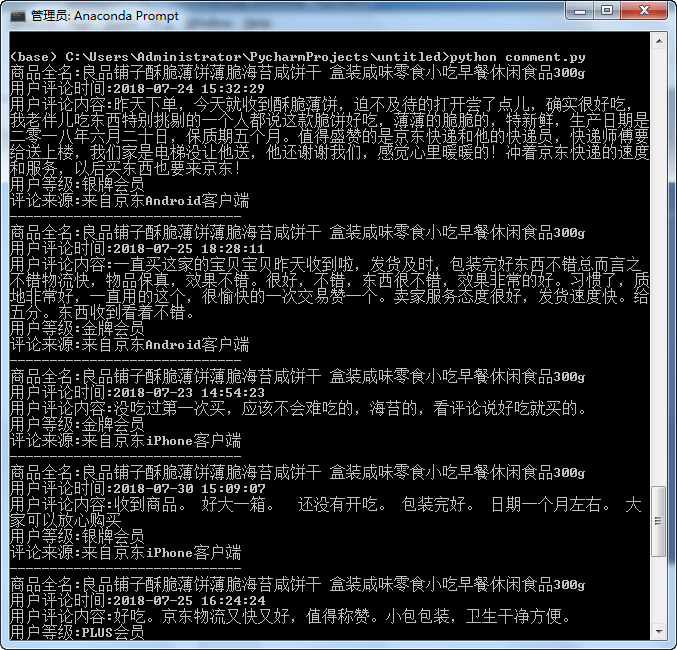
四、获得产品详情
使用python的正则表达式,获得产品详情
import requests
import json
import re
def get_product_desc(skuid):
product_desc_url = "https://cd.jd.com/description/channel?skuId={id1}&mainSkuId={id2}&cdn=2&callback=showdesc".format(id1=skuid, id2=skuid)
response = requests.get(product_desc_url)
response = response.text.replace("showdesc(", "")
response = response.replace(")", "")
re_dict = json.loads(response)
content = re_dict["content"]
# 将正则表达式编译成Pattern对象
pattern = re.compile(r"""<img.*?>""", re.I)
match = pattern.findall(content)
# print(match[0])
for each_match in match:
print(each_match)
if __name__ == "__main__":
get_product_desc(1110663)