

项目需求:
有成千上万个域名,想查询哪些域名已经被百度收录,收量的页面数量有多少?
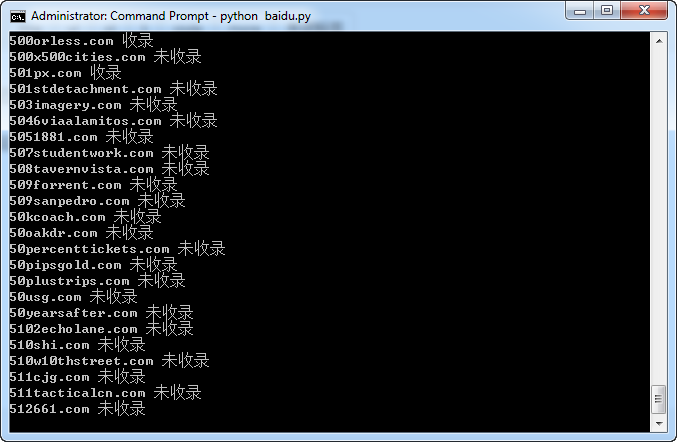
直接找网上的代码改了一下,基本满足需求了,运行界面如下:
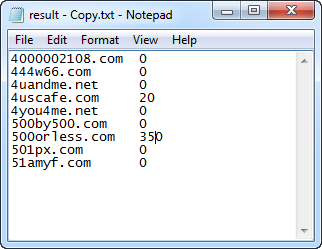
将被百度收录的域名保存下来:
最开始在网上找的是通过"http://www.baidu.com/s?wd="的方式来查询百度收录的,不过这种方式查询的百度收录准确率只有90%多,有些用site命令查找并没有收录的网站也会被误判为收录,而且无法取到百度的收录量。后来通过抓取site页面结果的方式,可以准确地取到收录量,而且数据也精确了。
运行代码时,第一次我将sleep设为3秒,跑了一个晚上没问题,第二天到10点多钟卡住不动了。第二次晚上开跑,跑了2个多小时,又卡在那儿不动了。估计是查询太过频繁IP被百度禁止了。
由于是自己用的,我两种方式的代码都保存了下来,所以下面的代码变成了一个大杂烩。其实真要用的话,拿check_index_number这个函数稍微改改就可以了,可以精简很多代码。
import requests
import time
from random import randint
from lxml import etree
HEADERS = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"X-Forwarded-For": '%s:%s:%s:%s' % (randint(1, 255),
randint(1, 255), randint(1, 255), randint(1, 255)),
"Content-Type": "application/x-www-form-urlencoded",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Connection": "keep-alive"}
def check_index_number(url):
"""
查询网址被百度收录的数量
:param url: 要查询的网址
:return: 返回被百度收录的数量
"""
url_a = 'https://www.baidu.com/s?wd=site%3A'
url_b = '&pn=1&oq=site%3A52pojie.cn&ie=utf-8&usm=1&rsv_idx=1&rsv_pq=dd6157d100015d1f&rsv_t=9a3eHncH3YeAeoblNqMm1f3%2FAQsJeSgF03XLXg6VDz6VqSprqUL8lGGO3us'
joinUrl = url_a + url + url_b
# print joinUrl #拼接URL
html_Doc = requests.get(joinUrl, headers=HEADERS)
response = etree.HTML(html_Doc.content)
try:
index_number = response.xpath('//*[@id="1"]/div/div[1]/div/p[3]/span/b/text()')[0]
except:
index_number = 0
pass
return index_number
def getUrl(filepath):
with open(filepath, "r") as f:
f = f.readlines()
return f
def getHtml(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def isindex(link):
url = link.replace("http://", "").replace("/", "%2F")
url = "http://www.baidu.com/s?wd=" + url
html = getHtml(url)
with open("result.txt", 'a') as f:
if "很抱歉,没有找到与" in html or "没有找到该URL" in html:
print(link, "未收录")
else:
print(link, "收录")
indexed_number = check_index_number(link)
f.write(link+'\t'+str(indexed_number)+'\n')
def main():
filepath = "20181105-new.txt" # 待查询的URL链接文本,一行一个
urls = getUrl(filepath)
for url in urls:
url = url.strip()
try:
isindex(url)
except:
pass
time.sleep(2)
if __name__ == '__main__':
main()