

从archive下载网站有三种方法:
一个Ruby语言写的小工具,可以从archive网站下载任何网站,开源,免费,强烈推荐!
二、warrick
收费的,$15一个网站。
这个我也用了,它还有一个Archivarix CMS,介绍挺不错的。
在他们网站提取200个以下的文件是免费的,超过200个文件要收费,我试了一下,不过提取一个70多个文件的网站非常慢。而且不知道什么原因,提取到的网站没有图片。
也是收费的,一个网站$15,具体没有测试了。
最后自己选了wayback-machine-downloader ,下面是详细的安装过程:
A step by step help for windows users (win8.1 64bit for me) new to Ruby, here is what I did to make it works :
一)安装ruby
到rubyinstaller.org/downloads 下载rubyinstaller-2.3.3-x64.exe安装文件,然后安装。
二)下载 wayback-machine-downloader
下载wayback-machine-downloader,下载地址:github.com/hartator/wayback-machine-downloader/archive/… ,然后解压缩。
三)安装wayback-machine-downloader
在开始菜单搜索"Start command prompt with Ruby"这个启动项目,然后打开命令行窗口。执行以下命令
gem install wayback_machine_downloader
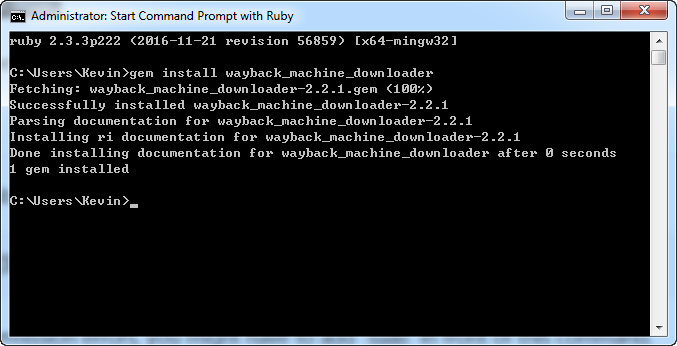
四)下载网站
在命令行中输入以下命令,开始下载网站。
wayback_machine_downloader https://seotoolsaccess.com
不过,我第一次使用的时候就碰到以下的错误提示:
Getting snapshot pagesC:/Ruby23-x64/lib/ruby/2.3.0/net/http.rb:882:in `rescue in
block in connect': Failed to open TCP connection to web.archive.org:80 (A conne
ction attempt failed because the connected party did not properly respond after
a period of time, or established connection failed because connected host has fa
iled to respond. - connect(2) for "web.archive.org" port 80) (Errno::ETIMEDOUT)
真晕啊,好像是因为墙,archive.com在国内访问不了的缘故,所以这脚本在国内根本用不了。
没办法,只能用其它办法,想到之前自己花$9买的virmach VPS还一直没有使用呢,配置如下:
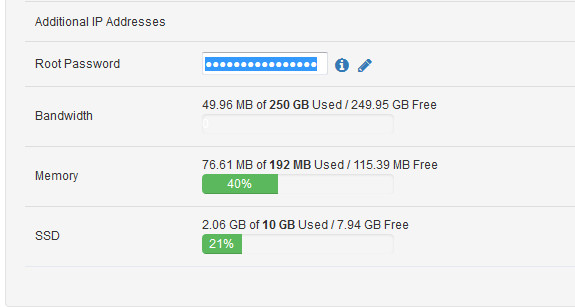
就用这个吧!
Updated on Jan-20-2019:
还是不要用这个下载网站了,速度太慢了,根本受不了!最后改用linode2,即尾号为113的vps.
(一)连接VPS
以前没用过Xshell,今天特意试用了一下,在自己经常混的一个论坛找到了坛友提供的绿色版本,一连接就连接成功了。
不过不得不说的是,这么便宜的VPS,那速度是非常慢,输入一条命令都不顺畅,
(二)执行以下代码:
apt-get install ruby gem install wayback_machine_downloader wayback_machine_downloader https://seotoolsaccess.com
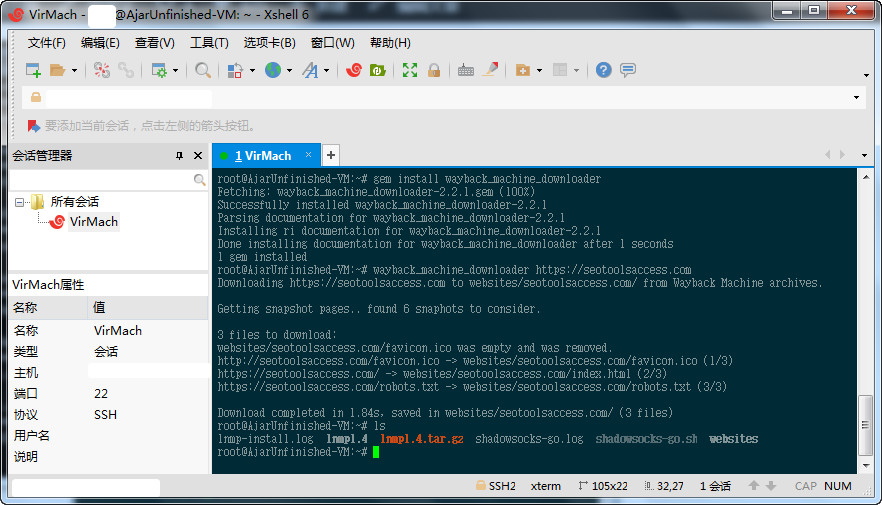
如果你要压缩文件夹,可以使用以下命令:
#压缩文件夹 tar zcvf FileName.tar.gz DirName
如果你要下载指定日期的数据,可以使用:
wayback_machine_downloader https://acrepairvannuys.net --from 20170711190606 --to 20180410120203 #复制数据 cp -ri /home/websites/acrepairvannuys.net/* /home/wwwroot/www.acrepairvannuys.net/
小提示:
1.你在哪下文件夹下面执行上面的命令,就会在当前文件夹下面生成一个叫websites的文件夹,里面有你的域名命名的文件夹,里面就是下载的数据。
2.用不同的日期可以得到不同的结果,我测试了一下三个日期,分别下载到了6个网页、42个网页、244个网页(不限定日期)。
3.下载的网站在本地无法正常显示,因为css文件调用的原因,所以必须传到网站才能显示效果。
(三)下载网站
打开Sftp.exe,输入ssh登陆的账号,密码就可以连接到VPS。
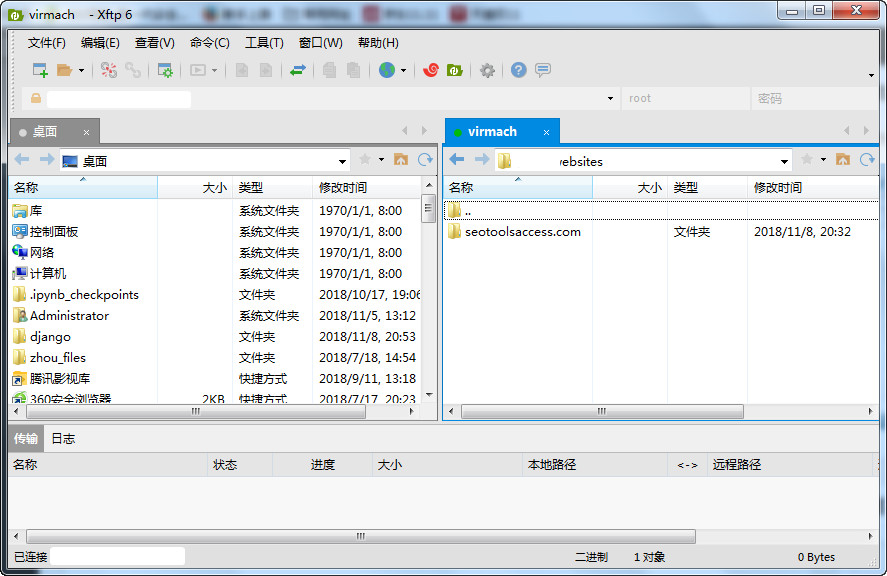
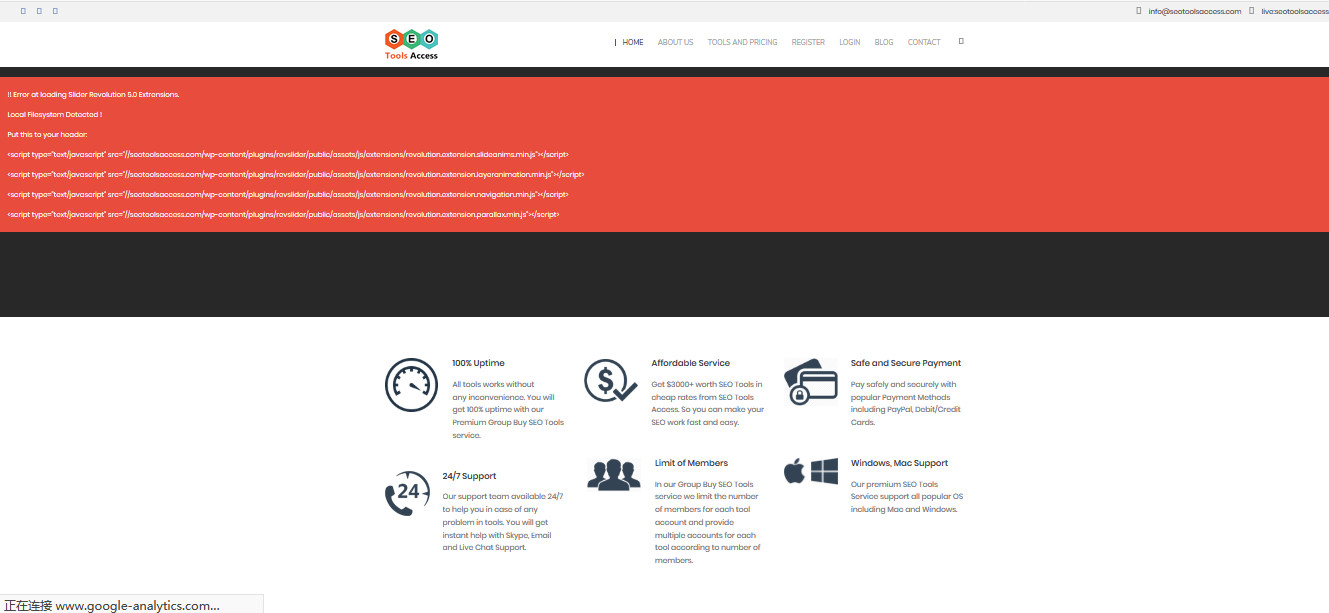
(四)预览效果
打开下载的网站,可以看到效果。除了部分代码有问题,其他一切显示正常。
(五)下载单个文件
我使用以下的命令
wayback_machine_downloader http://www.charteroakstatecollege.org/Charter-Oak-State-College-bookstore-hours.php --exact-url
结果输出成这样了:
1 files to download:
http://charteroakstatecollege.org/Charter-Oak-State-College-bookstore-hours.php/ -> websites/www.charteroakstatecollege.org/Charter-Oak-State-College-bookstore-hours.php/index.html (1/1)
参考:https://segmentfault.com/q/1010000008986220