

一、基本
网址:https://www.joinquant.com
自己用过的jupyter在登陆后的首页--“我的研究文件”里面。
二、取数
通过在线jupyter取数
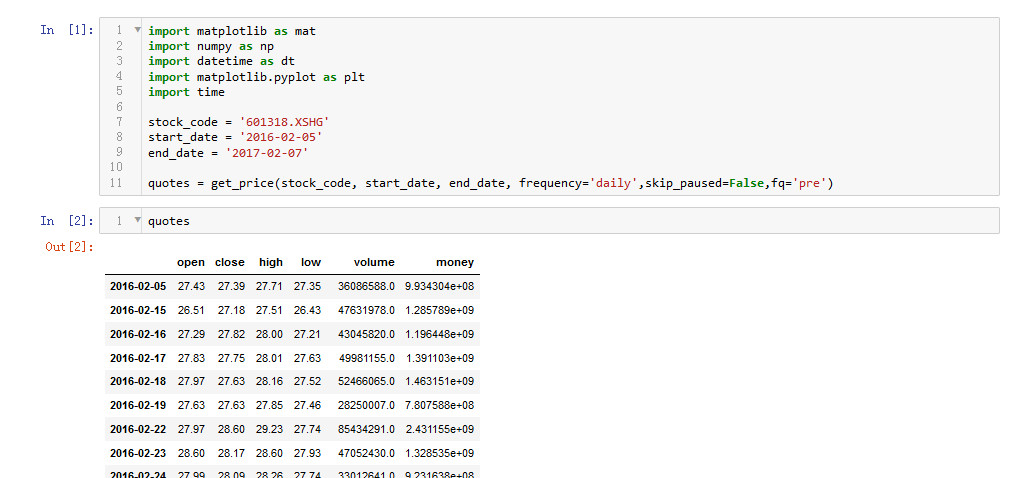
import matplotlib as mat import numpy as np import datetime as dt import matplotlib.pyplot as plt import time stock_code = '601318.XSHG' start_date = '2016-02-05' end_date = '2017-02-07' quotes = get_price(stock_code, start_date, end_date, frequency='daily',skip_paused=False,fq='pre')
取到的数据:
三、Zen theory
最开始一直在寻找在聚宽的在线jupyter中添加自己的module的方法,后来一想,不是将代码直接贴上去就可以了吗?
终于运行成功了。
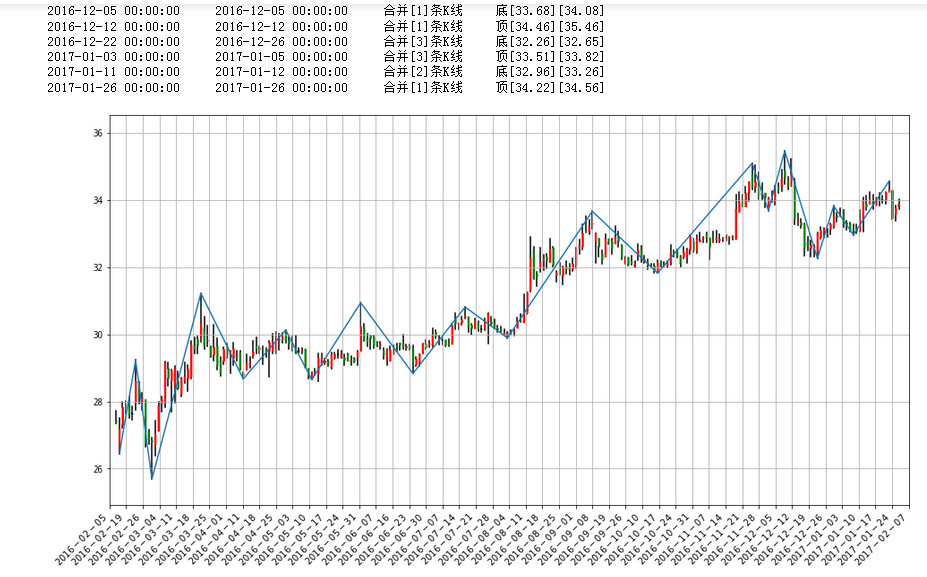
希望不要有未来函数才好。
作个备份:
可参考:https://www.joinquant.com/view/community/detail/432ee4491ab65d96a3c77a17a228b128
https://www.cnblogs.com/medik/p/9788987.html
四、移植
1.保存聚宽的数据
注意:最后面的index =True要加上,不然第一列数据没有了。
quotes.to_csv("002.csv",encoding = 'utf-8', index =True)
然后到https://www.joinquant.com/research就可以看到这个csv文件与其他的ipynb文件在一起。
2.本地读取
import pandas as pd
quotes = pd.read_csv('002.csv') # 读取训练数据
print(quotes)
这样来看前面的序号只是显示来用的,并不真正存在。
3.Debug
将数据移植到本地就花费了不少的时候,明明在聚宽的jupyter上可以正常运行的,但是在本地电脑上运行的时候出现五花八门的各种错误。
包括:
name 'nan' is not defined
#暂时设为0
NameError: name 'array' is not defined
#将88行的array改为np.array
还有其他的,比如:
AttributeError: 'long' object has no attribute 'strftime'
NameError: name 'long' is not defined
由上面的name 'long' is not defined发现,这个应该是python2.x版本的,于是尝试python2.x。
五、改用数据源
1.注册
用自己的手机注册了一个账号a-14。
2.安装
我是按https://blog.csdn.net/ebzxw/article/details/80687612这里的方法,下载安装包,用pip setup.py install 安装的。
2.本地下载数据
from jqdatasdk import *
auth('138xxxxxx','xxxx')
stock_code = '601318.XSHG'
start_date = '2016-02-05'
end_date = '2017-02-07'
def test():
quotes = get_price(stock_code, start_date, end_date, frequency='daily',skip_paused=False,fq='pre')
print(quotes)
if __name__ == '__main__':
test()
如果要获取分钟数据:
df = get_price(stock_code, start_date, end_date, frequency='30m', fields=['open','close','high', 'low'],skip_paused=False,fq='pre')
终于取到数据了。

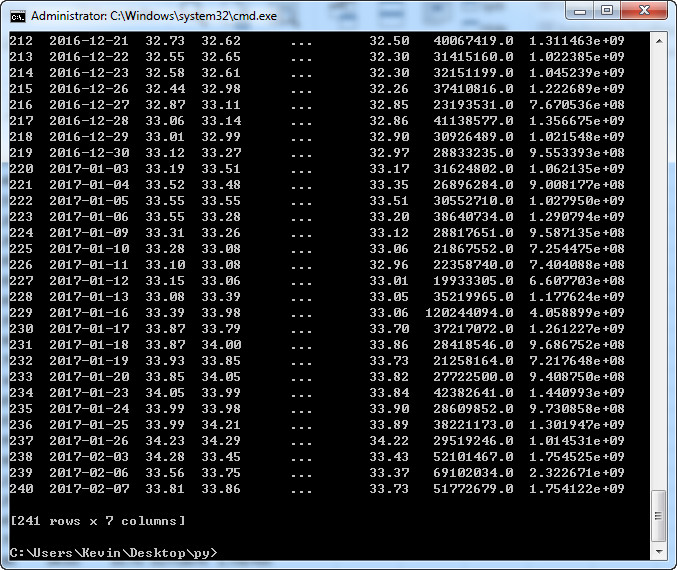
而且经查看,数据类型为
从图中看到原来的数据有7列,真的有问题。
3.成果展示:
这时终于没有错误了。
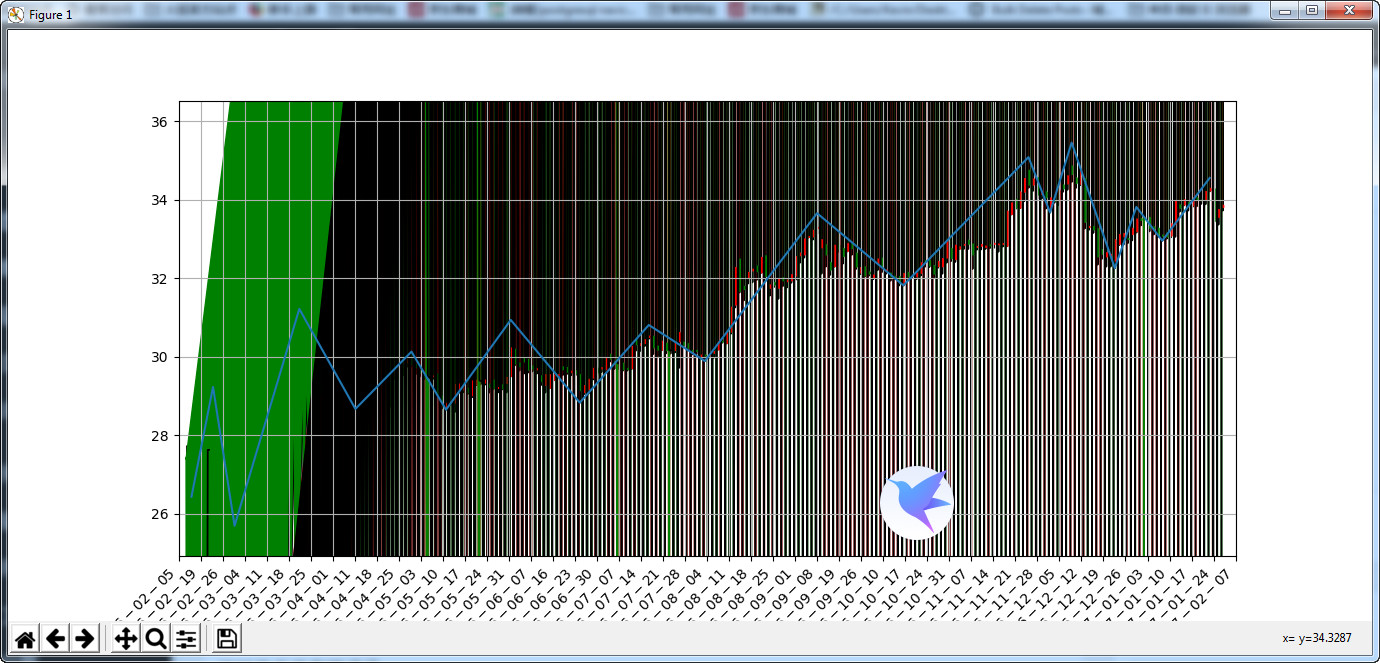
4.代码分析
(1)KLineDTO
df = get_price(stock_code, start_date, end_date, frequency='30m', fields=['open','close','high', 'low'],skip_paused=False,fq='pre')
date_list = df.index.tolist()
data_per_day = df.values.tolist()
k_line_list = []
''' 将dataframe数据组装进入KLineDTO的列表中 '''
for index in range(len(date_list)):
date_time = date_list[index]
open_price = data_per_day[index][0]
close_price = data_per_day[index][1]
high_price = data_per_day[index][2]
low_price = data_per_day[index][3]
k_line_dto = KLineDTO(date_time,
date_time,
date_time,
open_price, high_price, low_price, close_price)
k_line_list.append(k_line_dto)
print(k_line_list[index].open)
这样就取到数了。
使用print(k_line_list[index]),则看到的是:
(2016-12-07 14:30:00, 2016-12-07 14:30:00, 2016-12-07 14:30:00)
(2016-12-07 15:00:00, 2016-12-07 15:00:00, 2016-12-07 15:00:00)
(2016-12-08 10:00:00, 2016-12-08 10:00:00, 2016-12-08 10:00:00)
(2016-12-08 10:30:00, 2016-12-08 10:30:00, 2016-12-08 10:30:00)
2.MergeLineDTO
这个和上面的差不多
下面的代码同样打印出时间(不过只有两个时间)
merge_line_list = find_peak_and_bottom(k_line_list, "down")
for index in range(len(merge_line_list)):
print(merge_line_list[index])
将最后一行改为:print(merge_line_list[index].is_peak)
就可以看到打印出的效果了。
查看merge_line_list
for m_line_dto in merge_line_list:
print(m_line_dto.begin_time.strftime('%Y-%m-%d %H:%M:%S') + " -- " +
m_line_dto.end_time.strftime('%Y-%m-%d %H:%M:%S') + "**" +
m_line_dto.is_peak + "**" + m_line_dto.is_bottom + "**" +
str(m_line_dto.stick_num))
结果:
2016-12-15 14:30:00 -- 2016-12-15 14:30:00**N**N**1
2016-12-15 15:00:00 -- 2016-12-16 10:00:00**N**Y**2
2016-12-16 10:30:00 -- 2016-12-16 11:00:00**Y**N**2
2016-12-16 11:30:00 -- 2016-12-16 11:30:00**N**N**1
2016-12-16 13:30:00 -- 2016-12-16 14:00:00**N**Y**2
2016-12-16 14:30:00 -- 2016-12-16 14:30:00**Y**N**1
2016-12-16 15:00:00 -- 2016-12-16 15:00:00**N**N**1
2016-12-19 10:00:00 -- 2016-12-19 10:00:00**N**Y**1
2016-12-19 10:30:00 -- 2016-12-19 11:30:00**Y**N**3
六、尝试python3.x
在python3.x环境直接使用pip install jqdatasdk安装。然后调试出现:NameError: name 'long' is not defined的错误。
直接将173行的long改成了int。
然后可以运行,但图仍然有错误:
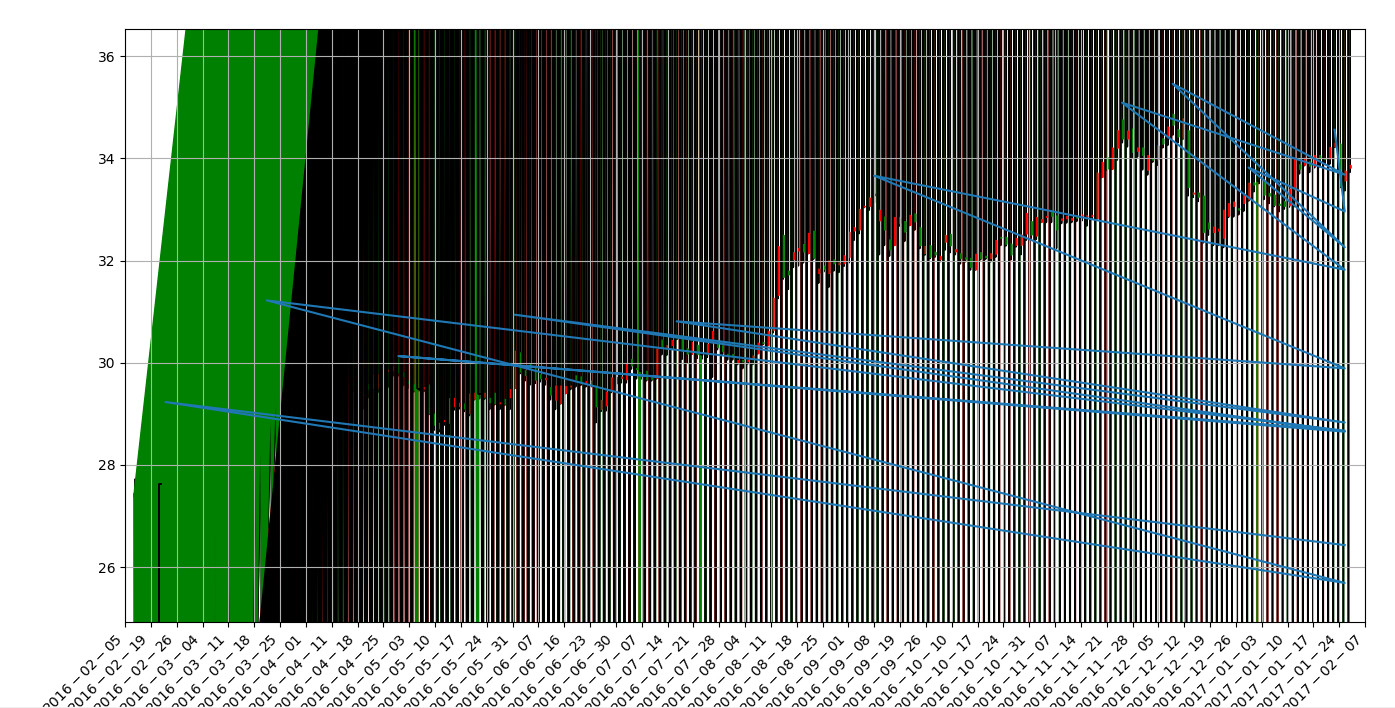
https://www.joinquant.com/help/api/help?name=JQData