

一、每日涨跌统计以及每日收益率的特征
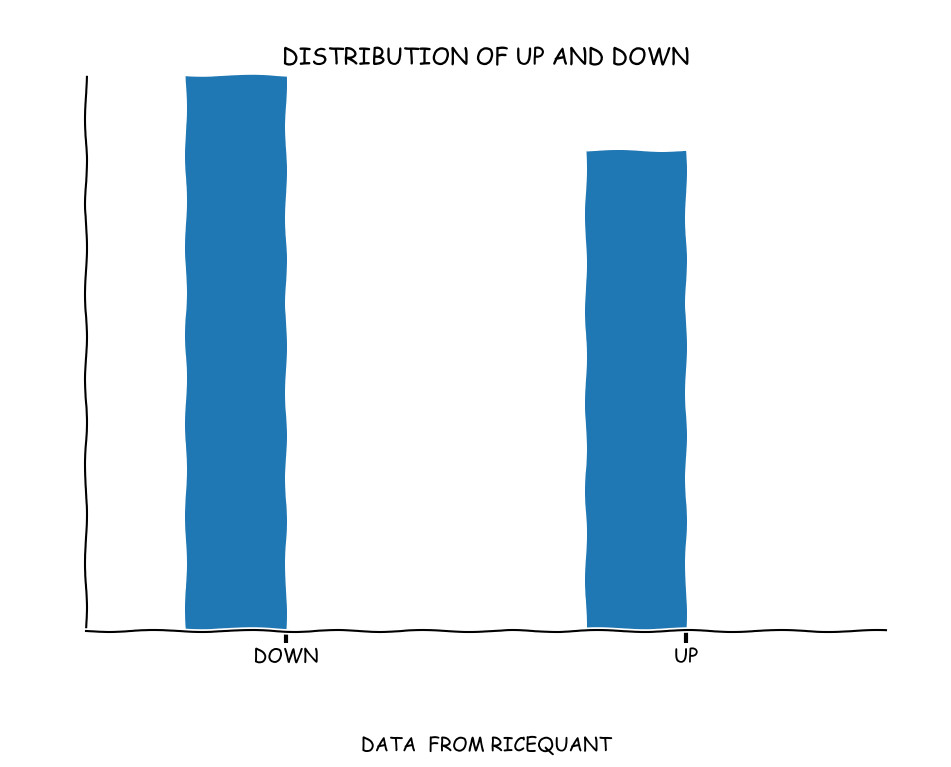
所用的数据是从2010年4月19日到2017年2月7日的if数据。总共有1652个交易日,有888个交易日是上涨的,而764个交易日下跌。
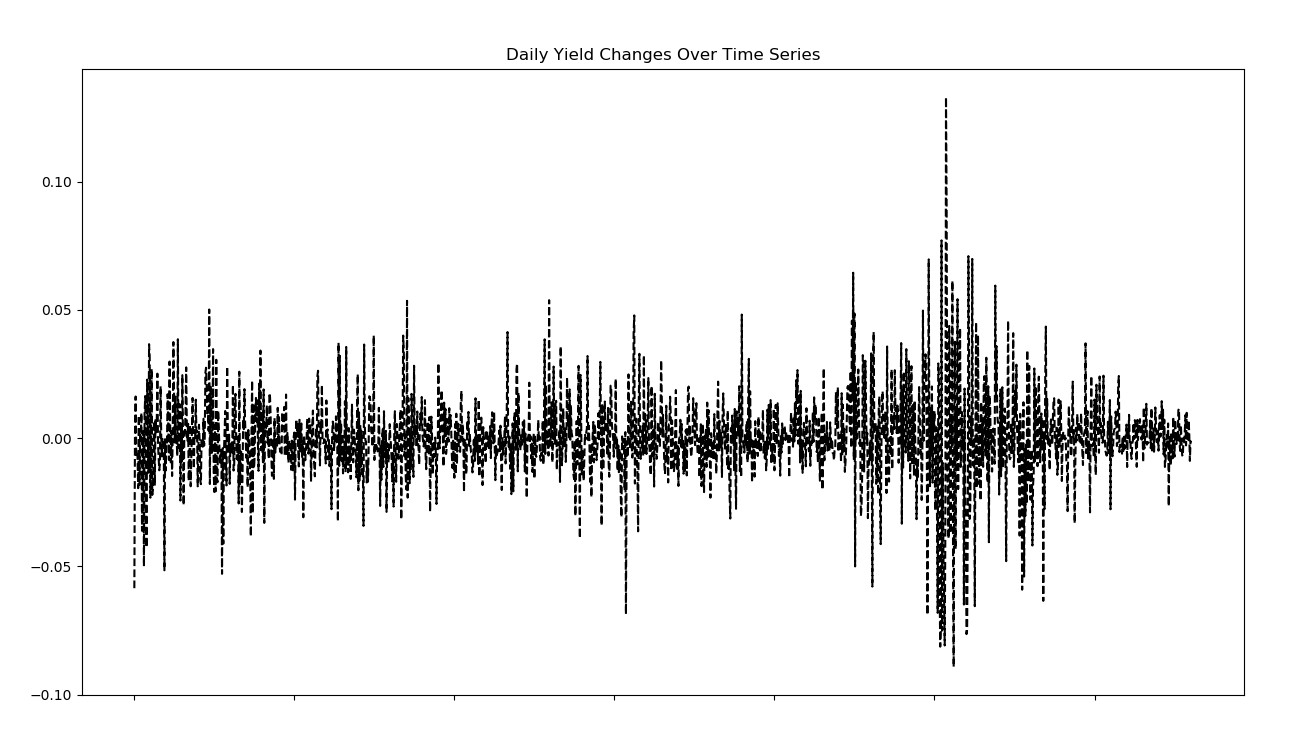
IF单日涨幅最大为13.29个点(大奇迹日),单日跌幅最大为8.9个点(大盘跌停)。
二、代码
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# df = rd.get_price('CSI300.INDX', '2005-01-01', '2015-07-25').reset_index()[['OpeningPx', 'ClosingPx']]
df = pd.read_csv('if.csv',index_col =0)
#当收盘价高于开盘价返回"True"
up_and_down = df['ClosingPx'] - df['OpeningPx'] > 0
#每日收益率
rate_of_return = (df['ClosingPx'] - df['OpeningPx']) / df['OpeningPx']
#每日涨跌统计
up_and_down_statistic = up_and_down.value_counts()
print(up_and_down_statistic)
print("\n")
# with plt.xkcd():
# fig = plt.figure(figsize=(10, 8))
# ax = fig.add_axes((0.1, 0.2, 0.8, 0.7))
# ax.bar([-0.125, 1.0-0.125], [up_and_down_statistic[0], up_and_down_statistic[1]], 0.25)
# ax.spines['right'].set_color('none')
# ax.spines['top'].set_color('none')
# ax.xaxis.set_ticks_position('bottom')
# ax.set_xticks([0, 1])
# ax.set_xlim([-0.5, 1.5])
# ax.set_ylim([0, up_and_down_statistic.max()])
# ax.set_xticklabels(['DOWN', 'UP'])
# plt.yticks([])
# plt.title("DISTRIBUTION OF UP AND DOWN")
# fig.text(
# 0.5, 0.05,
# 'DATA FROM RICEQUANT',
# ha='center')
# plt.show()
print(rate_of_return.describe())
rate_of_return.plot(kind='line', style='k--', figsize=(15, 10), title='Daily Yield Changes Over Time Series')
# plt.show()
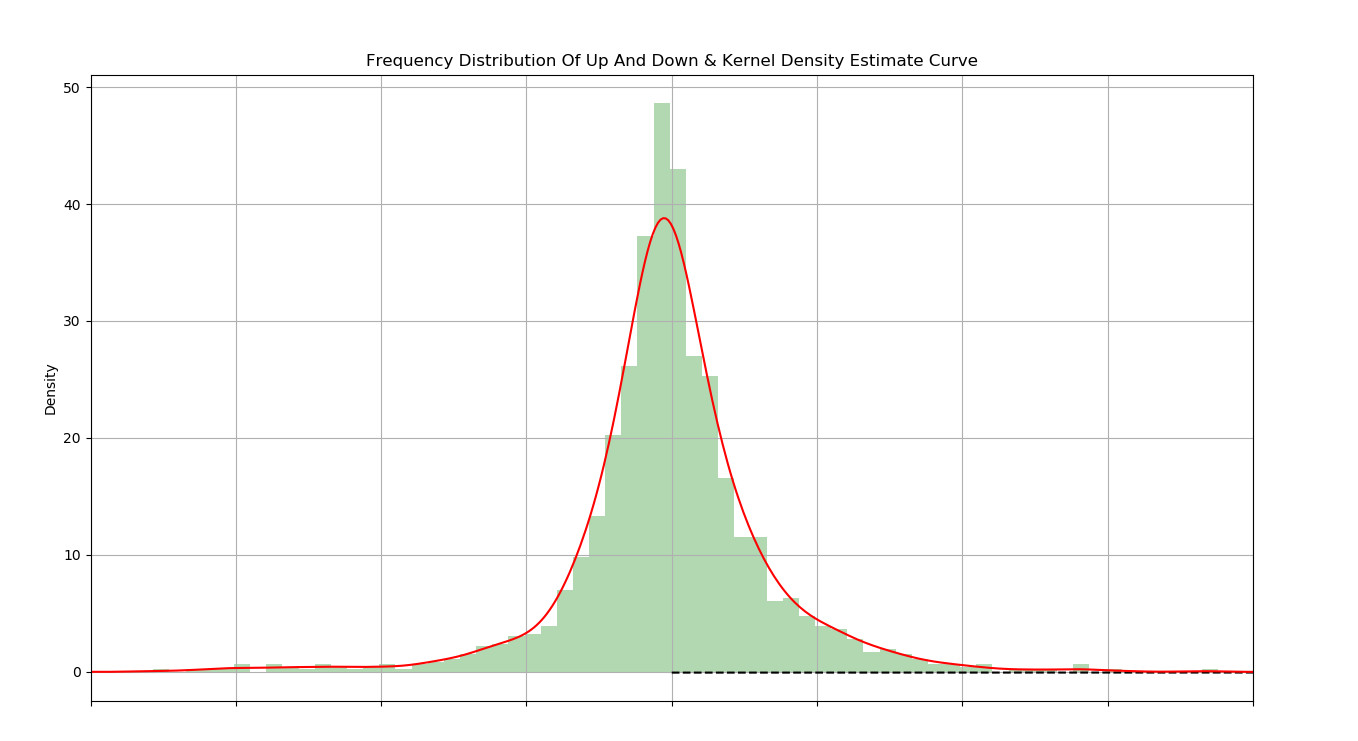
## Frequency distribution of up and down
rate_of_return.hist(bins=80, alpha=0.3, color='g', normed=True)
## Kernel Density Estimate
rate_of_return.plot(kind='kde', xlim=[-0.1, 0.1], style='r', grid=True, figsize=(15, 10), title='Frequency Distribution Of Up And Down & Kernel Density Estimate Curve')
plt.show()
三、机器学习
1.解决错误ValueError: Expected 2D array, got 1D array instead
这是由于在新版的sklearn中,所有的数据都应该是二维矩阵,哪怕它只是单独一行或一列(比如前面做预测时,仅仅只用了一个样本数据),所以需要使用.reshape(1,-1)进行转换。
参见:https://www.jianshu.com/p/60596270e94e
2.解决错误AttributeError: 'list' object has no attribute 'reshape'
原因是list不能使用reshape,需要将其转化为array,然后就可以使用reshape了。
参见:https://blog.csdn.net/yijiaobani/article/details/102957153
3.结果展示
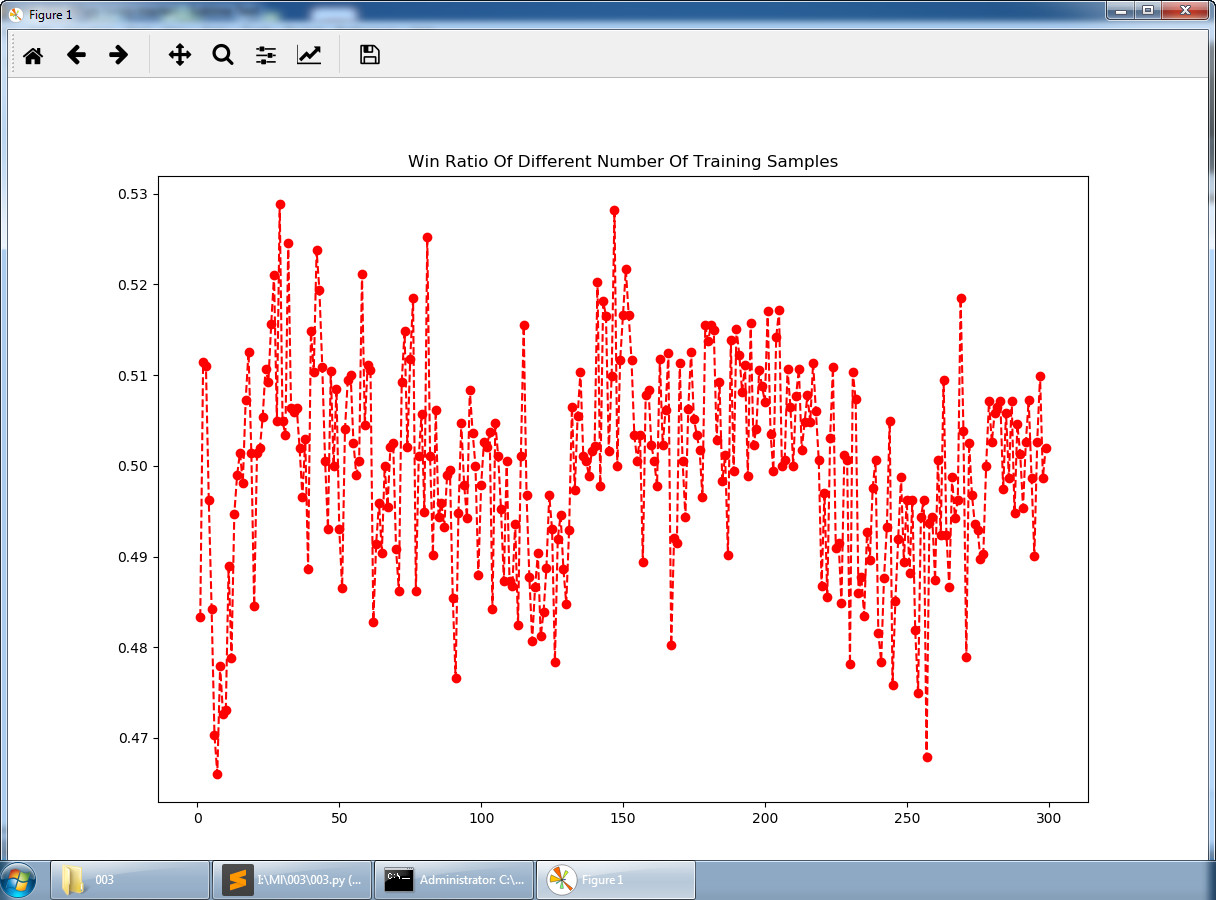
4.代码
from __future__ import division
from sklearn.ensemble import RandomForestClassifier
from collections import deque
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#df = rd.get_price('CSI300.INDX', '2005-01-01', '2015-07-25').reset_index()[['OpeningPx', 'ClosingPx']]
df = pd.read_csv('if.csv',index_col =0)
up_and_down = df['ClosingPx'] - df['OpeningPx'] > 0
win_ratio2 = []
samples_list = [x for x in range(300) if x != 0]
window = 2
for samples in samples_list:
clf = RandomForestClassifier()
X = deque(maxlen = samples)
y = deque(maxlen = samples)
prediction = 0
test_num = 0
win_num = 0
current_index = 600
for current_index in range(current_index, len(up_and_down)-1, 1):
fact = up_and_down[current_index+1]
X.append(list(up_and_down[(current_index-window): current_index]))
y.append(up_and_down[current_index])
if len(y) >= samples:
test_num += 1
clf.fit(X, y)
prediction = clf.predict(np.array(list(up_and_down[(current_index-window+1): current_index+1])).reshape(1, -1))
if prediction[0] == fact:
win_num += 1
#print win_num/test_num
win_ratio2.append(win_num/test_num)
fig = plt.figure(figsize=(12, 10))
plt.plot(samples_list, win_ratio2,'ro--')
plt.title('Win Ratio Of Different Number Of Training Samples')
plt.show()
四、涨跌时间窗口的选择
(1)结果
稳定震荡于0.5扔硬币的概率左右。
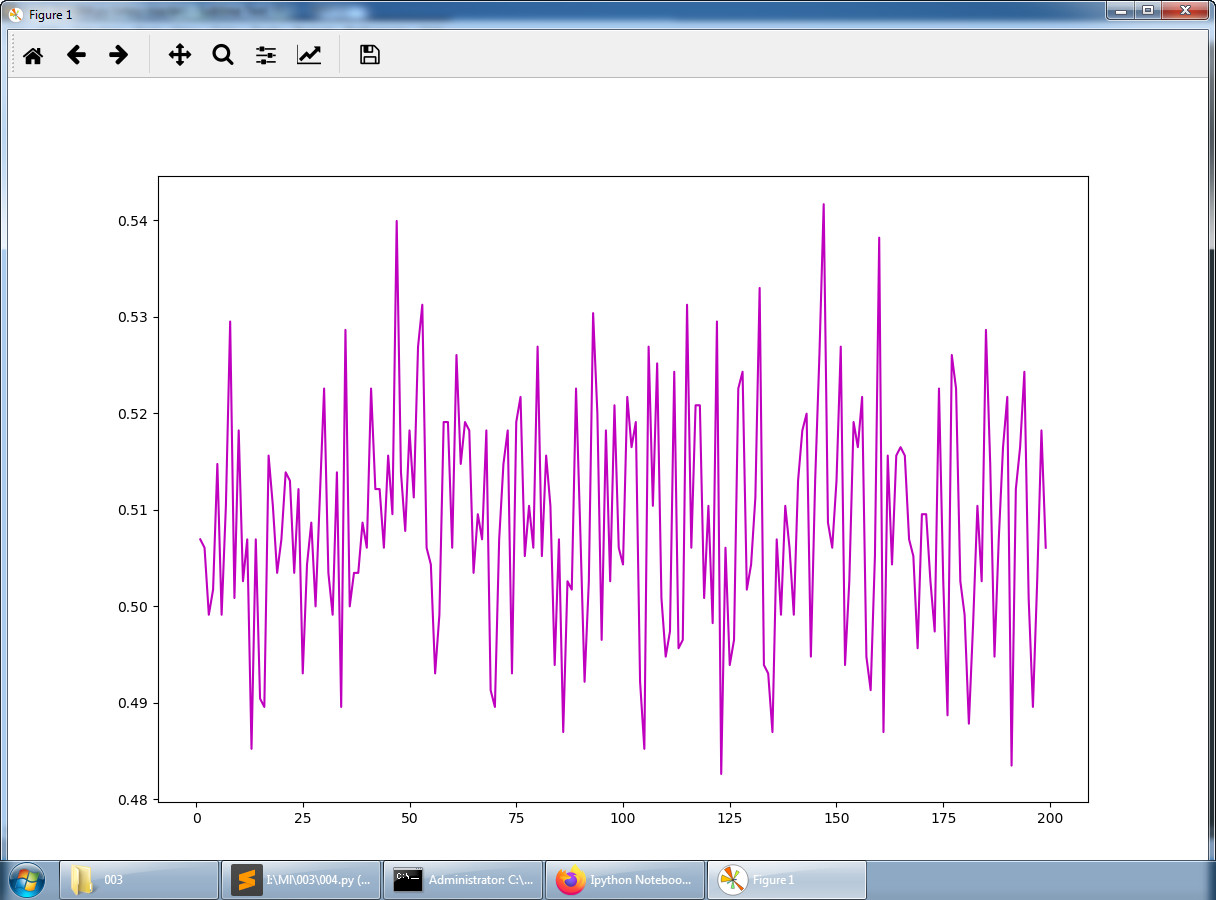
(2)代码
from __future__ import division
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from collections import deque
import matplotlib.pyplot as plt
#df = rd.get_price('CSI300.INDX', '2005-01-01', '2015-07-25').reset_index()[['OpeningPx', 'ClosingPx']]
df = pd.read_csv('if.csv',index_col =0)
up_and_down = df['ClosingPx'] - df['OpeningPx'] > 0
win_ratio = []
window_list = [x for x in range(200) if x != 0]
for window in window_list:
clf = RandomForestClassifier()
X = deque(maxlen = 100)
y = deque(maxlen = 100)
prediction = 0
test_num = 0
win_num = 0
current_index = 400
for current_index in range(current_index, len(up_and_down)-1, 1):
fact = up_and_down[current_index+1]
X.append(list(up_and_down[(current_index-window): current_index]))
y.append(up_and_down[current_index])
if len(y) >= 100:
test_num += 1
clf.fit(X, y)
prediction = clf.predict(np.array(list(up_and_down[(current_index-window+1): current_index+1])).reshape(1, -1))
if prediction[0] == fact:
win_num += 1
#print win_num/test_num
win_ratio.append(win_num/test_num)
fig = plt.figure(figsize=(12, 10))
plt.plot(window_list, win_ratio, 'm')
plt.show()
#Win Ratio Of Different Time Window'
参考:https://www.ricequant.com/community/topic/103/ipython-notebook-research-alpha%E4%B8%8B%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B8%80%E7%9E%A5-%E5%85%B3%E4%BA%8E%E8%B7%8C%E8%B7%8C%E6%B6%A8%E6%B6%A8%E7%9A%84%E6%80%9D%E8%80%83