

一、机器学习
对于 Quant 来说, Financial Modeling 和传统的机器学习方法有什么联系和区别?
从Quantitative Modeling的角度来说,有两大主流的方向:Stochastic Calculus(随机微积分)和Statistical Learning(统计学习)。这两个主流方向基本涵盖了你所有可能用到的技术——随机微积分,或者说金融数学,提供了各种衍生产品的风险估计基础,也是处理新型资产定价的常用方式;而统计学习,则包罗计量经济学、时间序列分析和各种机器学习方法。我个人比较喜欢用Q measure世界和P measure世界来指代这两种方法,因为统计学习主要在真实概率空间进行分析,而随机微积分在基于无套利假定而设立的Q概率空间进行分析。
好吧,我相信你已经晕了——为什么在真实概率空间外,还会有一个Q概率空间,这不是一下子可以说清楚的问题,我就给一个简单的例子,剩下的如果你还有兴趣可以再自己研究:
假设现在只有两种资产,一种是股票,一种是债券,假设一年后这个世界只有两种情景,一种是好市场,一种是坏市场,各自出现的概率是60%和40%。我们画一个表格,就有:
t=0 | t=1 Good (60%) | t=1 Bad (40%)
Stock 1 | 1.2 | 0.8
Bond 1 | 1.1 | 1.1
表格里面的数字代表价格,比如第一行表示股票今天1元,一年后在好的情况下变成1.2元,而坏的情况下变成0.8元;第二行因为债券是固定收益,两种请都是10%的收益。

这样满足了理论微观经济学的各种假设,你就可以基于此概率去定价一个期权了,或者其它更加复杂的衍生产品。
这套体系由Arrow在1965年建立,之后他也成为了诺奖得主。而基于这一体系诞生了Black Scholes(1973)期权定价公式,在很长一段时间内被业界奉为圭臬。
但是这一体系太理论化了,在实际做交易的时候会缺少指导意义。就好比Wolf of Wall Street里面,Can you sell the pen now,那支笔有理论价值,比如市场同类的价格是多少,成本是多少,不能偏差太多,不然就有套利,但是你的交易价格可能远远偏离这个价格,因为这一单取决于购买者的现实需求,而这或许可以从历史交易数据中得出,这就是统计学习方法可以应用的场景。
在业界呆了一段时间后,我开始重新思考这个问题——为什么1960到2000年大量的金融研究在随机微积分领域开展,而2000年后,大量的金融研究开始应用越来越复杂的计量经济学和机器学习方法。我个人的看法是——早期数据的缺失,使得数学建模——随机微积分成为唯一可行的方法,而2000年后数据的蓬勃发展,使得统计学习成为可能。要知道Fama在1970写有效市场理论市场的数据是Dow Jones里面30支股票的10年日交易数据,这是当时的大数据,而现在,所有股票的每单级别的数据也不罕见了,数据——信息驱动研究的变化,在每个领域都是一样。这不难解释为什么机器学习逐渐主流了——30年前没有数据,何来金融统计分析?
这两种方法(Q世界与P世界)在一定假设下可以得到相同的结果,比如你设定同样的无套利、经济人理性等条件,随机微积分与统计学习可以得到非常接近的期权定价。但是统计学习的好处是,你知道这个世界的不完美,你可以随意放松无套利和理性交易这些太过严格的假设,依然获得鲁棒性不错的模型。
那么在今天的Quant世界,这两者的应用是怎样的呢?做风险和定价的Quant,还是采用传统的随机微积分为纲领,这种方法算出来的价格被交易员用来作为交易和对冲的指导,但是交易员的报价还是根据自己的判断来进行;在山的另一边,做程序化做市(Automatic Market Making)、资产配置或者高频交易的Quant,无一例外的活动在P世界——基于大数据和先进的机器学习来发现交易机会。
是信息行业的发展重塑了整个金融研究,但这不意外——要知道数百年前就是提前获得的关于英法战争结果信息帮助了罗斯柴尔德家族成为欧洲金融霸主——信息一直就是金融中最关键的edge。
从Quant自身来说,我觉得P世界——统计学习方向是未来,随着数据越来越多,实证方法很有可能长期成为主流——甚至随机微积分的传统强势领域也可能为之侵蚀。但是随机微积分领域的很多理论与方法是古典经济学的集大成之作,如果你想获得更好的直觉,这些是必须深入研究的,不然你很可能沦为反复在同一数据上使用不同的统计包碰运气的data miner。
Quant其实只是一种绝对理性和数量化分析思想的践行者。也许今天我说的这些是Quant需要的技能,5年后或许又有了全新的一套体系。要做好一个Quant,唯一必须的就是对理性的信仰和Unquenchable Curiosity。
作者:袁浩瀚
链接:https://www.zhihu.com/question/22221540/answer/22120516
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
二、高频
当KDB能储存一个月一个交易所所有的每笔级别的数据,并且能在几秒钟内用Q语言完成分析,各种新奇的研究开始出现。比如近两年的研究趋势就是很多教授拿到了交易所提供的账号级别分笔交易,并且可以利用来探测内幕交易等非法行为。另外就是市场微结构(Market Micro Structure)的研究取得了巨大的突破。学者和高频交易公司开始发现,拿着全体(Population)和每日抽样——日交易数据来看这个世界原来是这么的不一样。
如果说1962年在芝加哥大学Eugene Fama拿着Harry Ernst给的当时的大数据——30只Dow Jones股票10年的日行情数据——发现的是市场有效性(Market Efficiency),那么在1996年的冬天,MIT的新锐金融教授Andrew Lo拿着Nasdaq交易所全部股票的高频Tick级数据所发现的确是微观市场的无效性了——个股价格不总是那么随机的。
这篇论文叫《Econometric Models Of Limit-Order Executions》(Lo, MacKinlay and Zhang 2002),通篇讨论一个问题——一个限价单(Limit-Order)在这个市场中要被执行掉需要多久。
这篇论文的核心是一个回归,然后用了大量的因子。其中最统计显著的两个,一个很符合预期,那就是这个限价单的价格到Mid Price(Bid + Ask / 2 )的距离——不难理解,你卖得越便宜或者买得越贵,那么越容易成交。另外一个因子,就是所谓的Order Book Inbalance——用A股大仙的说法就是买卖盘压力差。
原论文中Andrew Lo将Bid(买盘)的合约数量和Ask(卖盘)的合约数量做了分离,成为了两个因子。但是一般实际操作中,人们常用价格加权压力数:
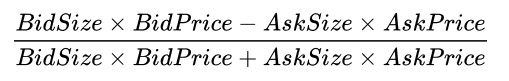
这个指数越大,代表上升的概率更大,反之越小。
这个指数不知道是什么时候开始在高频交易中流行起来,现在却成为美国市场最重要的Tick Level方向判定因子。具体有多准,在股票市场,用第一档盘口的数据算出来的这个指数判定能力有70%-80%;而在新型的债券电子市场,这个信息也可以准确预测85%左右的下一Tick的走向。这个指标是几乎所有美国自动化做市商的基础——从股票、股票期权到期货,商品及债券。
这个指标有三个关键的前提——第一,你采用的是严格的Tick数据,就是一旦有一单交易或者盘口有任何变化(价格、数量),你都有最新的盘口快照——你拥有全体(Population)数据;第二,你要用盘口第一档的数据;第三,你只用来判断涨或者跌的方向,而不是具体涨跌多少点。
第一点决定了在中国期货市场这种500ms一次的快照,数据无法做此类研究——因为这500ms里面盘口变化很多次,你拿到的不是全体数据;第二点是因为在盘口第一档的量是最真实的量——任何一个市场都有尝试放假的量在盘口实现某种目的的交易方法——但是一般情况下如果不是真心想成交,放盘口的人是少的——因为太容易成交了。但是必须要说明的是,我在国内市场看到过其有着反向的指示效果,卖盘越大,反而步步上扬——也许中国真的是一个有太多反身性定律的市场;第三点是判断涨跌要比点位容易太多,相信有着简单统计知识就可以理解。
但是一个坏消息是,尽管有着如此高达80%的判断能力,你也无法从这个信号中直接获利,需要做一些进一步的研究,原因此处不多述了。
合
我不知道Andrew Lo在实证研究这个因子得到那个回归后内心是什么感受,当我第一次用Tick数据测试过Order Inbalance这个因子后,第一个想到的就是拉普雷斯妖——那个在经典力学体系下可以预测未来的灵。有趣的是,我当时并不知道拉普雷斯妖这个概念——直到有一天我去找Peter Carr聊这个现象,在大量词不达意的描述这个感受后,他告诉我他高中哲学史上学过一个东西,叫做拉普雷斯妖,就是我想表达的那个智能的名字——请原谅我的无知。
有些书里面会把盘口的变化用一种很物理的方式来阐述——叫做”价格动力学“(Price Dynamics)——你下市场价的买单,卖盘被击穿,推动价格上扬,就好像你对一个纸板做功一样。我很喜欢这个名字,让两者的联系更加接近一点。
高频交易的盘口这个东西,很符合经典力学的各种假设,甚至你可以将手续费看作是摩擦力,而且基于计算机的鲁棒性的假设下,迷你黑洞——这种霍金认为的绝对随机性的制造机器——似乎也无法给的一个个单的成交带来随机性。
而大数据,是使得这个拉普雷斯妖浮出水面的关键工具——就像前面说的,只有Tick级别的数据才能验证这个效果。就好比在20世纪前由于科技的限制我们无法做到“测不准”一样,在Tick数据成为可用前,Eugene Fama也很难做这种频率的研究来探究市场微结构下的很多问题(注:我个人是市场有效性理论的信徒,但是我认为有效性理论从指数整体级别来看是存在,但是从局部个股级别来看,是可以被挑战的。正如前面提及,你能准确判断下一个Tick但是你很能基于此信号获利,讨论这个信号不代表其能带来超额收益)。
那剩下的20%的不确定性是什么——虽然我们有着Tick的盘口全体数据,但是我们不知道其它人此刻的想法和行为——异于拉普雷斯妖,我们并没有真正的全部信息——因此这是这部分随机性的来源。要获得所有市场参与者的想法在目前看来很难了,毕竟我们没有人是X教授。
以上,愚钝小生农耕之余随感一篇,余不一一。
夏至夜于纽约
https://zhuanlan.zhihu.com/p/19778754