

最近用wordpress做了一个小站,目的很简单就是要第一时间更新小说并发布到wordpress,本来是想用火车头解决的,但没有模块无赖之下,只有自己用python手写,本来是想用mysqldb直接插入的,但wordpress表单实在是有点麻烦,且远程速度有点慢。一想到python的主要思想是不要重复发明轮子,于是在pypi找到了wordpress_xmlrpc模块,主要功能就不说了,详见官网:http://python-wordpress-xmlrpc.readthedocs.org/en/latest/
目前wordpress_xmlrpc模块已经更新到了2.2版本,不过本人用的是1.5版本。懒的同学在centos下可以这样安装.
Wget https://pypi.python.org/packages/source/p/python-wordpress-xmlrpc/python-wordpress-xmlrpc-1.5.tar.gz --no-check-certificate
tar zxf python-wordpress-xmlrpc-1.5.tar.gz
cd python-wordpress-xmlrpc-1.5
python setup.py install
好了wordpress_xmlrpc模块就介绍到这儿,其它功能参考官网介绍。下面说一下程序思路。
1、用一个记事本记录已经抓取的URL。
2、再去抓这个页面看看,得到这个页面文章的全部URL。
3、for一下这个页面的全部URL是否在TXT中。
4、如果不在,就抓取这个URL的标题和内容发送到wordpress,并将URL写入txt中
5、最后用crontab自动任务,每天定时跑。
代码如下:(为防止某些同学不劳而获,用图片代替代码,红色部分别为网址,账号,密码,保存URL地址的txt)
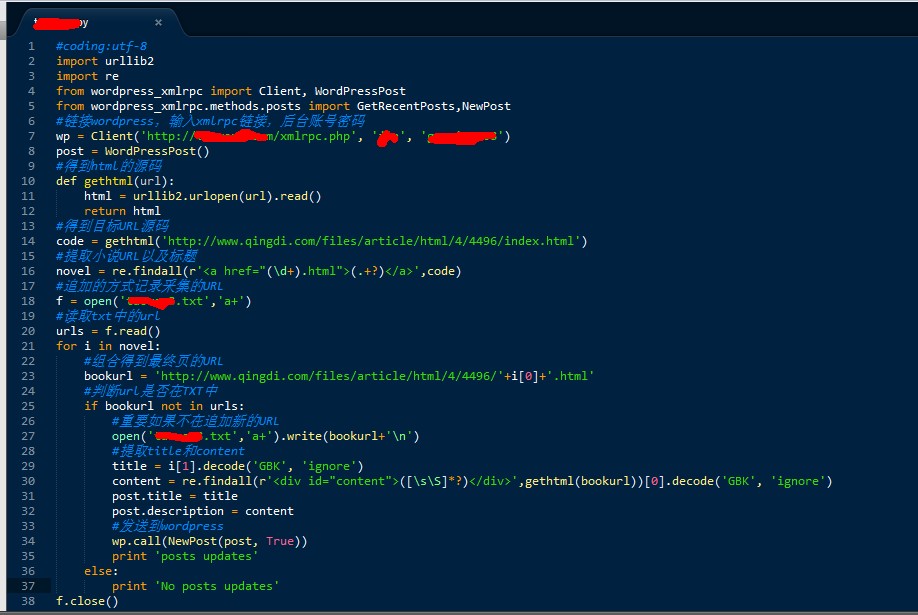
当然代码有一个小问题就是没有定义类别,其实wordpress_xmlrpc也是可以定义发布类别的,只是本人比较懒就在后台撰写默认文章分类设置了一下目录。
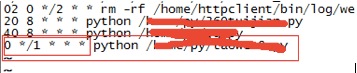
然后是crontab设为每小时定时更新一下。不会设置的自行脑补。
原载:http://www.itseo.net/direction/show-142.html
蜗牛博客(http://www.snailtoday.com)提供的源代码:
f = open('daily_posted.txt','r') #需要先建立posted.txt文件。
urls = f.read()
def update_dayly():
#news_url是要采集的网址。
for news_url in urls:
if news_url not in urls:
mylog.write_log('开始采集{}的数据'.format(news_url))
open('daily_posted.txt','a+',encoding='utf-8').write(news_url+'\n')
# scape_url(news_url)
result = get_details(news_url)
if result:
title = result[0]
post_content = result[1]
keyword_list = text2list(category+".txt")
title_keyword = random.sample(keyword_list,1)
if len(title) < 10:
title = "["+title_keyword[0] + "]"+ title
mylog.write_log("文章标题:" + title)
mylog.write_log("文章内容" + post_content)
mylog.write_log("正在发布第{}篇文章".format(n))
post_wordpress(title,post_content,category,title_keyword[0])
mylog.write_log("已经完成第{}篇文章的发布..........".format(n))
mylog.write_log("*"*20)
else:
mylog.write_log('当前文章之前已经发布过,略过......')
mylog.write_log('-'*70)