

学习目标:
- 掌握采集时翻页功能的实现。
- 掌握采集详细页面内容的方法
- 掌握运用Navicat可视化界面建立Sqlite数据库、数据表的方法。
- 掌握运用Scrapy从建立爬虫到写入Sqlite数据库的全部流程。
测试环境:
win7 旗舰版
Python 3.5.2(Anaconda3 4.2.0 64-bit)
一、创建项目及爬虫
创建一个名为teachers的项目。并且在spiders下面使用下面的命令新建一个teacher.py文件。
scrapy genspider teacher http://ggglxy.scu.edu.cn
系统会自动调用"basic"模板生成teacher.py文件,并自动生成以下的代码:
# -*- coding: utf-8 -*-
import scrapy
class Teacher2Spider(scrapy.Spider):
name = 'teacher2'
allowed_domains = ['http://ggglxy.scu.edu.cn']
start_urls = ['http://http://ggglxy.scu.edu.cn/']
def parse(self, response):
pass
二、设定items.py文件,定义要采集的数据
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class TeachersItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() #姓名 position = scrapy.Field() #职称 workfor = scrapy.Field() #所属系 email = scrapy.Field() #email link = scrapy.Field() #详细页链接 desc = scrapy.Field() #简介
三、编写teacher.py爬虫文件
注意:"item['name']="后面的div前面是没有//的。
import scrapy
import hashlib
from scrapy.selector import Selector
from teachers.items import *
class Teachers(scrapy.Spider):
name="tspider"
allowed_domains=["ggglxy.scu.edu.cn"]
start_urls=[
'http://ggglxy.scu.edu.cn/index.php?c=article&a=type&tid=18&page_1_page=1',
]
def parse(self,response):
for teacher in response.xpath("//ul[@class='teachers_ul mt20 cf']/li"):
item=TeachersItem()
item['name']=teacher.xpath("div[@class='r fr']/h3/text()").extract_first()
item['position']=teacher.xpath("div[@class='r fr']/p/text()").extract_first()
item['email']=teacher.xpath("div[@class='r fr']/div[@class='desc']/p[2]/text()").extract_first()
item['workfor']=teacher.xpath("div[@class='r fr']/div[@class='desc']/p[1]/text()").extract_first()
href=teacher.xpath("div[@class='l fl']/a/@href").extract_first()
request=scrapy.http.Request(response.urljoin(href),callback=self.parse_desc)
request.meta['item']=item
yield request
next_page=response.xpath("//div[@class='pager cf tc pt10 pb10 mobile_dn']/li[last()-1]/a/@href").extract_first()
last_page=response.xpath("//div[@class='pager cf tc pt10 pb10 mobile_dn']/li[last()]/a/@href").extract_first()
if last_page:
next_page="http://ggglxy.scu.edu.cn/"+next_page
yield scrapy.http.Request(next_page,callback=self.parse)
def parse_desc(self,response):
item=response.meta['item']
item['link']=response.url
item['desc']=response.xpath("//div[@class='desc']/text()").extract()
yield item
关于request.meta:
Scrapy采用的是回调(callback)的方式,把请求处理交给下一次请求,在请求时用meta传递参数。
Request(url=item_details_url, meta={'item': item},callback=self.parse_details)
可传递简单类型参数或对象类型参数。
还可以传递多个参数:
yield Request(url, meta={'item': item, 'rdt': rdt, 'comments':cmt,'rewards':rewards,'total': total, 'curpage': cur}, callback=self.parse)
我们看一下相应代码的执行效果:
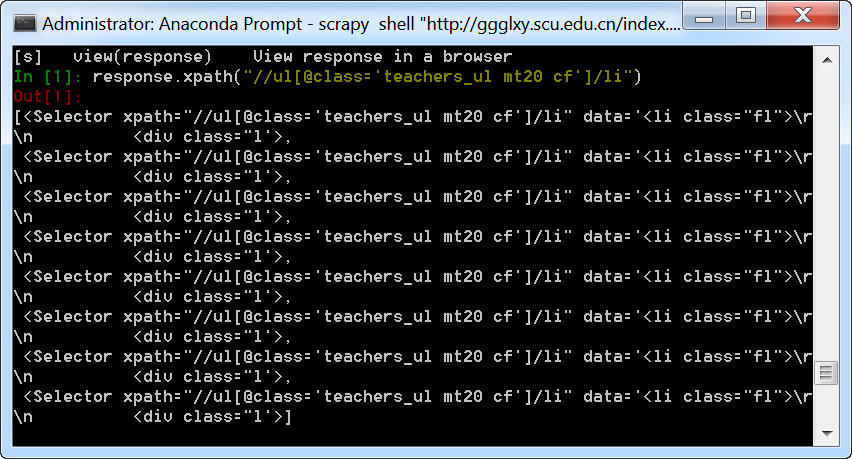
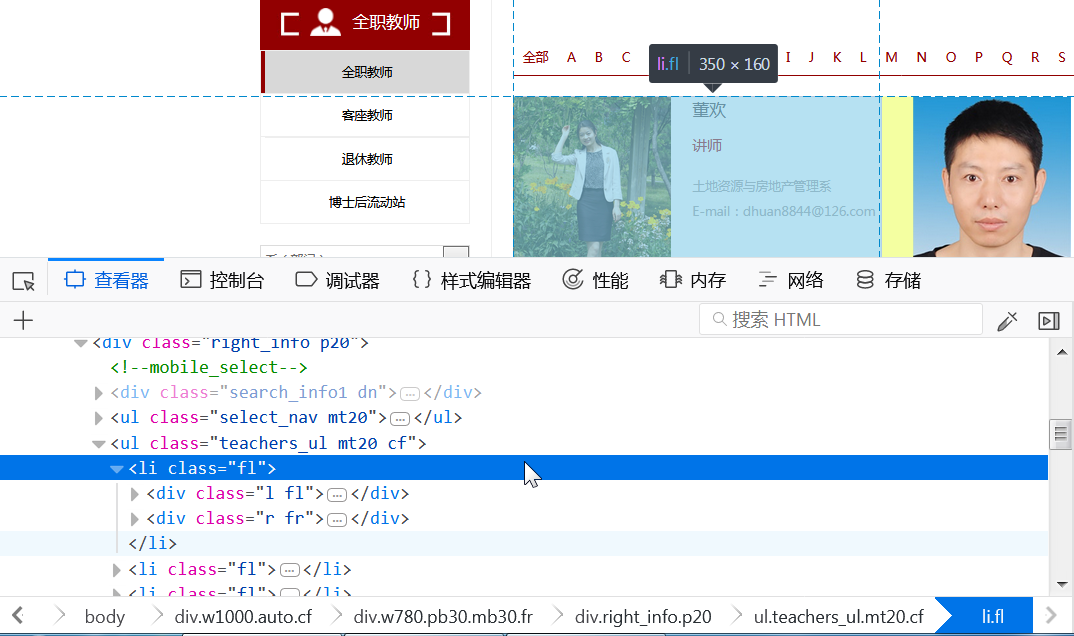
可以看到,class="fl"对应的是左边的区块,然后又分成了l fr和r fr两个部分。
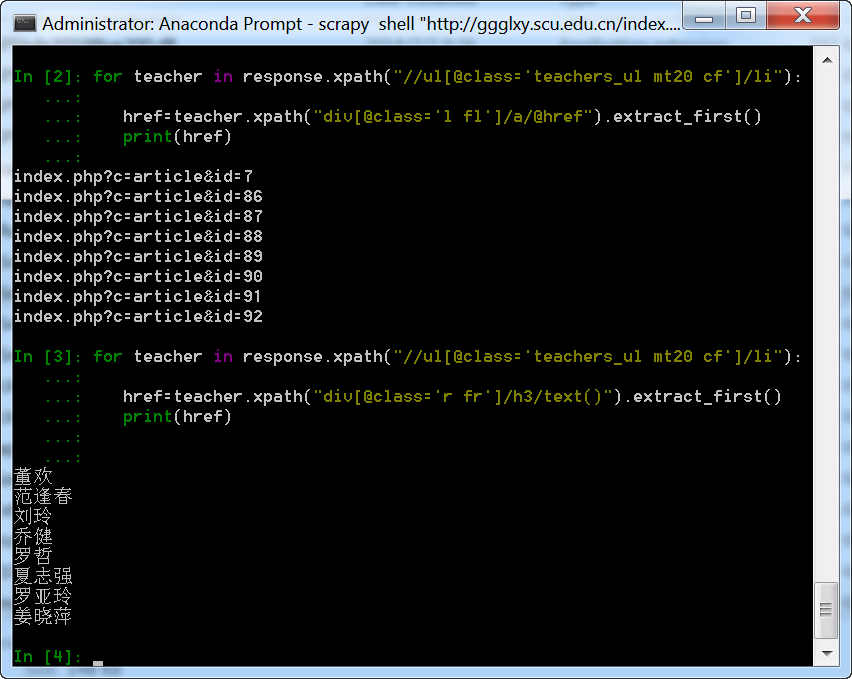
我们可以通过print函数测试代码:
四、执行爬虫
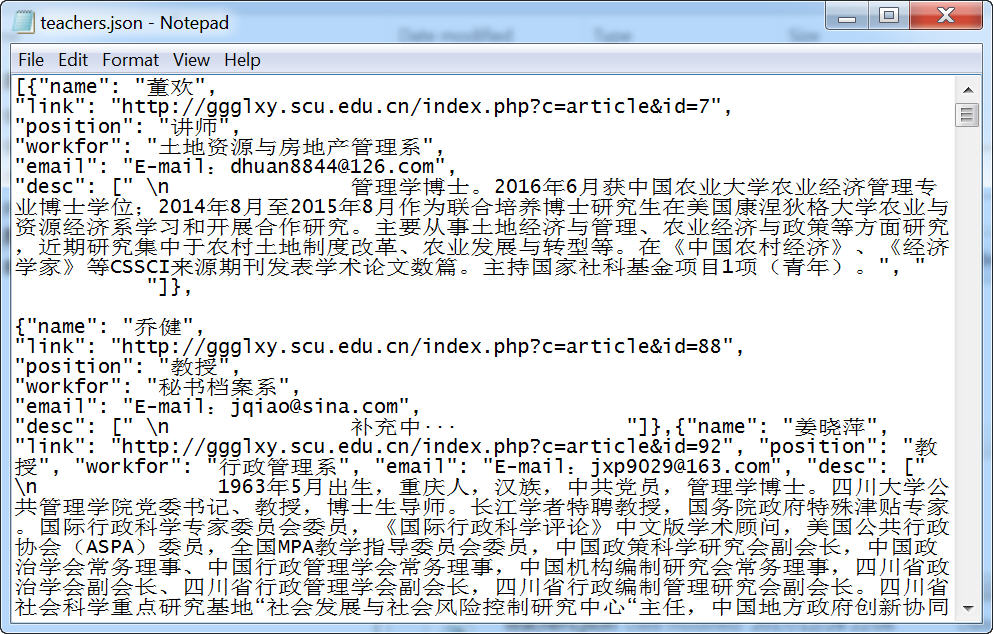
scrapy crawl tspider -o teachers.json -s FEED_EXPORT_ENCODING=utf-8
五、查看结果
https://www.jianshu.com/p/ad6bf3f2a883
下面是自己实践的流程及代码:
一、创建一个名为tech2的项目
scrapy startproject tech2
二、利用scrapy genspider命令生成teacher2.py文件。
cd tech2 scrapy genspider example example.com
注意事项:生成的文件中我用的是
allowed_domains = ['http://ggglxy.scu.edu.cn']
由于加了一个http://,所以导致后面实现翻页功能的时候老是失败,找了半天才发现原来是加了http://的原因。所以记住这行代码不要加http://。
三、修改items.py文件
import scrapy
class Tech2Item(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
rank = scrapy.Field()
depart = scrapy.Field()
email = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
四、teacher2.py文件
在抓取desc的时候,抓取到的内容有一个换行符号“/n”,入库时因为“/”无法入库,通过加上“normalize-space”得到解决。
import scrapy
from tech2.items import Tech2Item
class Teacher2Spider(scrapy.Spider):
name = 'teacher2'
allowed_domains = ['ggglxy.scu.edu.cn']
start_urls = ['http://ggglxy.scu.edu.cn/index.php?c=article&a=type&tid=18&page_1_page=1/']
def parse(self, response):
for teacher in response.xpath("//ul[@class='teachers_ul mt20 cf']/li"):
item = Tech2Item()
item['name'] = teacher.xpath("div[@class='r fr']/h3/text()").extract_first()
item['rank'] = teacher.xpath("div[@class='r fr']/p/text()").extract_first()
item['email'] = teacher.xpath("div[@class='r fr']/div[@class='desc']/p[2]/text()").extract_first()
item['depart'] = teacher.xpath("div[@class='r fr']/div[@class='desc']/p[1]/text()").extract_first()
href = teacher.xpath("div[@class='l fl']/a/@href").extract_first()
request = scrapy.http.Request(response.urljoin(href), callback=self.parse_desc)
request.meta['item'] = item
yield request
next_page = response.xpath("//div[@class='pager cf tc pt10 pb10 mobile_dn']/li[last()-1]/a/@href").extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
def parse_desc(self, response):
item = response.meta['item']
item['link'] = response.url
item['desc'] = response.xpath("normalize-space(//div[@class='desc']/text())").extract_first()
yield item
五、修改pipiline.py
这个可以作为模板,以后需要使用时只需要修改数据库名称(即tbase.sqlite)、表格名称即可。
import sqlite3
class Tech2Pipeline(object):
def open_spider(self, spider):
self.con = sqlite3.connect("tbase.sqlite")
self.cu = self.con.cursor()
def process_item(self, item, spider):
print(spider.name, 'pipelines')
insert_sql = "insert into tbase (name,rank,depart,email,desc) values('{}','{}','{}','{}','{}')".format(item['name'], item['rank'],item['depart'],item['email'],item['desc'])
print(insert_sql) # 为了方便调试
self.cu.execute(insert_sql)
self.con.commit()
return item
def spider_close(self, spider):
self.con.close()
六、在settings.py文件中开启pipeline,将下面的代码去除注释即可(按快捷键“CTRL+/”。
ITEM_PIPELINES = {
'tech2.pipelines.Tech2Pipeline': 300,
}
七、建立一个sqlite数据表
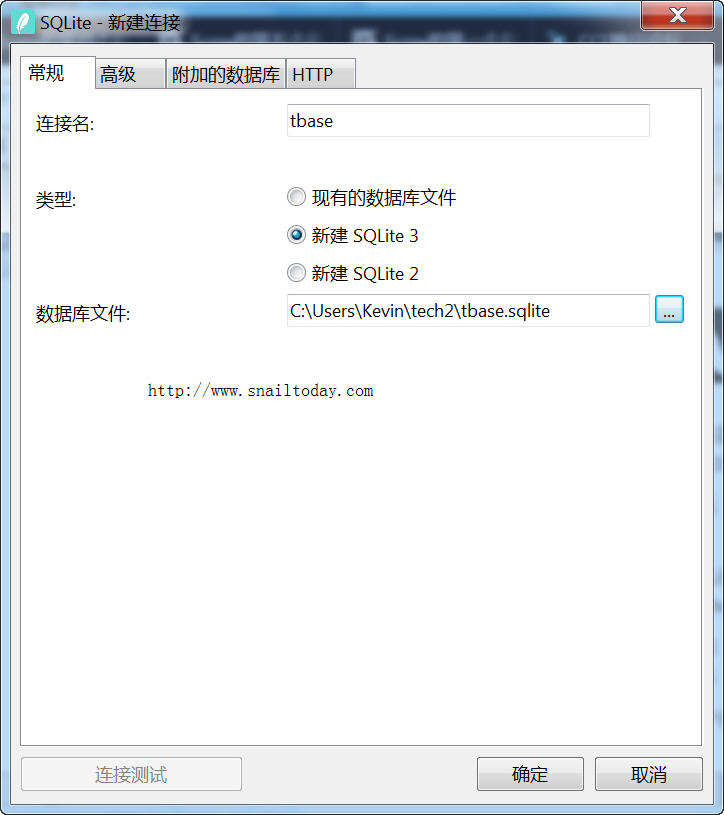
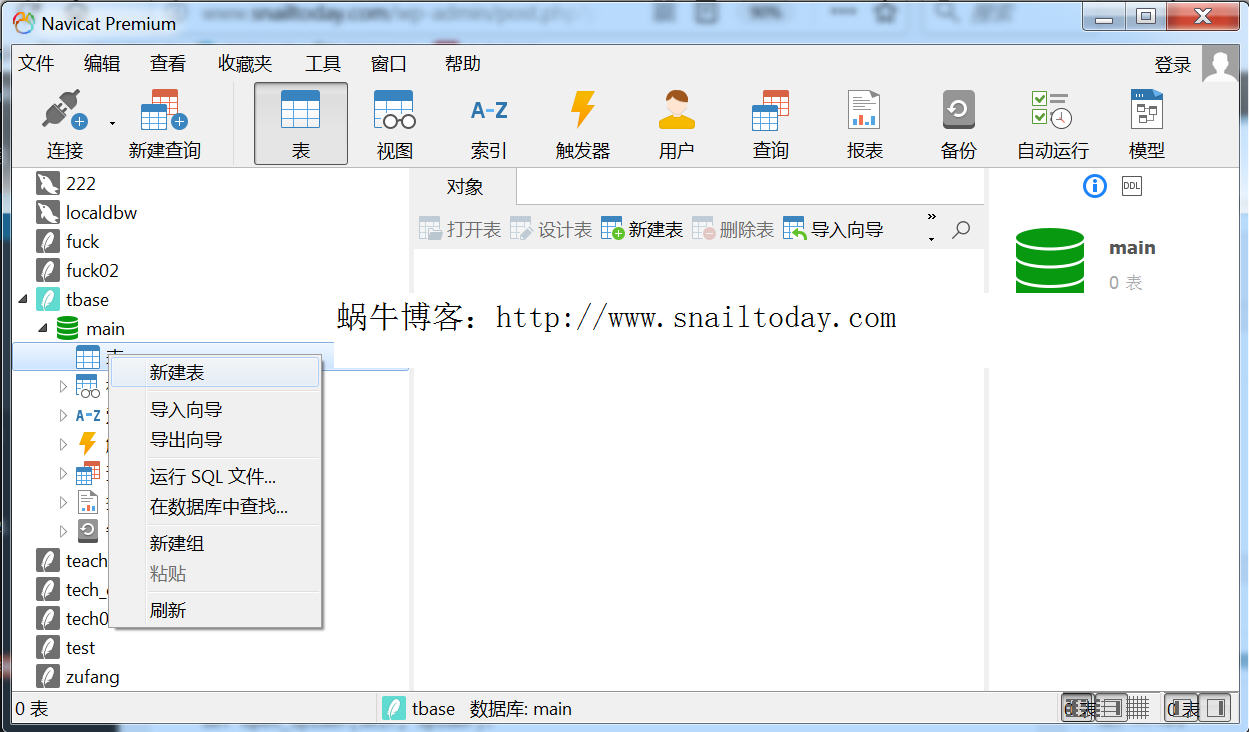
通过单击鼠标右键,在弹出的对话框中执行“添加字段”功能,为表格添加五个字段。
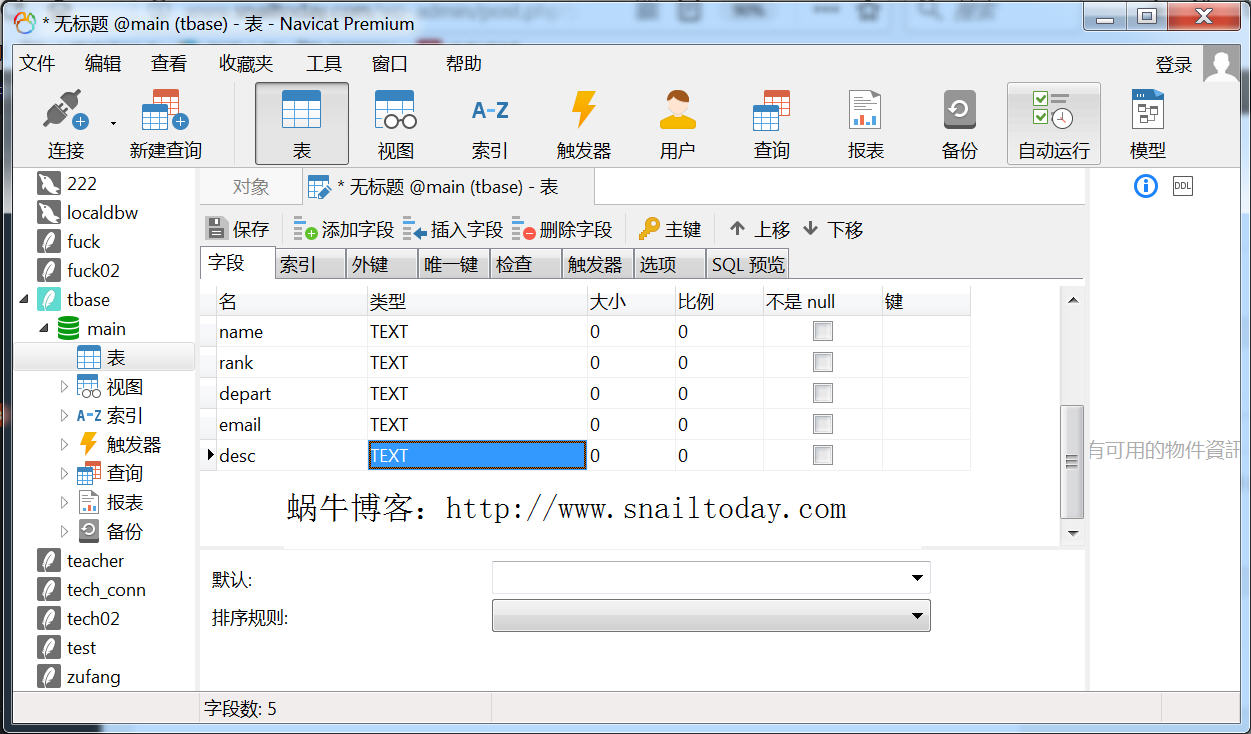
点击保存,输入表格名称
八、运行爬虫
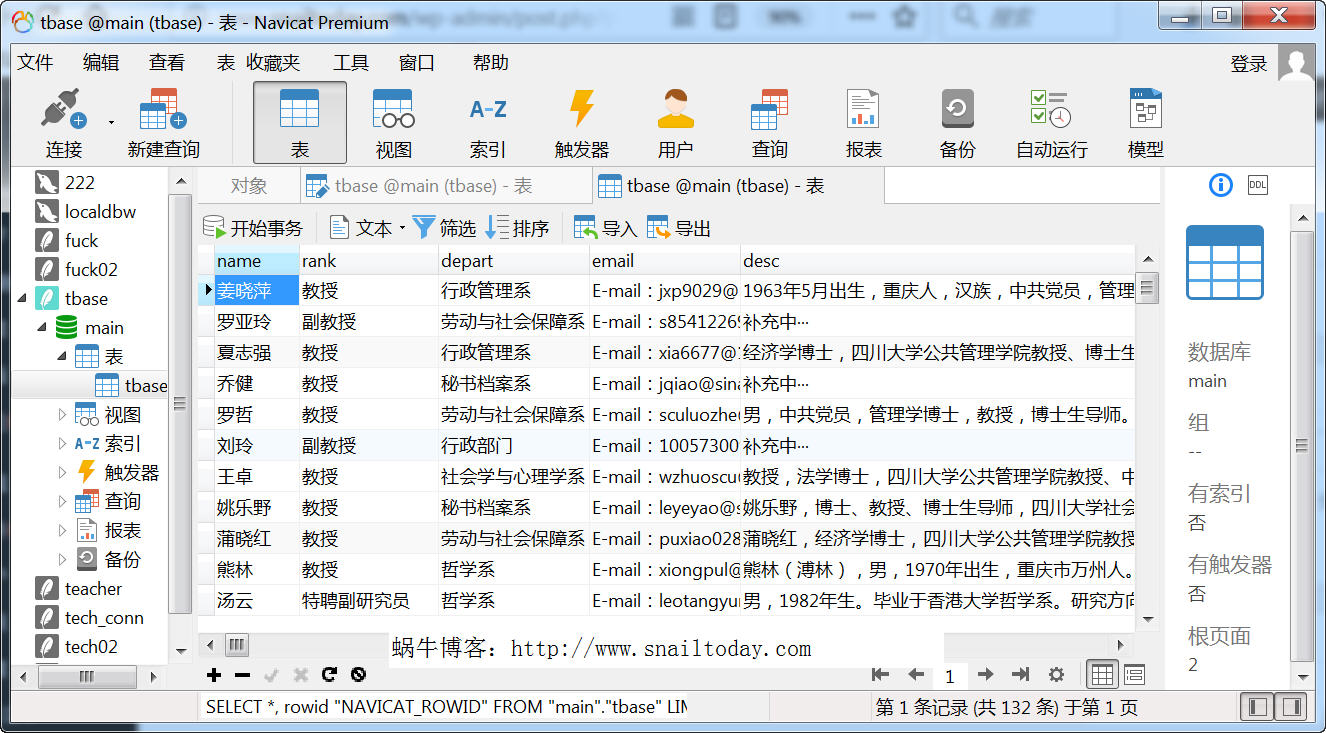
打开tbase这张表,可以看到数据已经入库。
补充:
另一个版本的teacher2.py
import scrapy
from tech2.items import Tech2Item
class Teacher2Spider(scrapy.Spider):
name = 'teacher2'
allowed_domains = ['http://ggglxy.scu.edu.cn']
start_urls = ['http://ggglxy.scu.edu.cn/index.php?c=article&a=type&tid=18&page_1_page=1/']
def parse(self, response):
item = Tech2Item()
name_list = response.xpath("//h3[@class='mb10']/text()").extract()
rank_list = response.xpath("//p[@class='color_main f14']/text()").extract()
depart_list = response.xpath("//div[@class='desc']/p[1]/text()").extract()
email_list = response.xpath("//div[@class='desc']/p[2]/text()").extract()
url_list = response.xpath("//div[@class='l fl']/a/@href").extract()
for i, j,k,l,m in zip(name_list, rank_list,depart_list,email_list,url_list):
item['name'] = i
item['rank'] = j
item['depart'] = k
item['email'] = l
item['url'] = m
yield item
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。