今天在测试一个程序的时候,出现了如下的错误:
UnicodeEncodeError: 'gbk' codec can't encode character '\xdb' in position 0: ill
egal multibyte sequence
又是编码的问题,所以不得不学习一下python的编码问题,而且将它搞明白的时候了。
一、背景知识
首先学习一下基础知识:
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
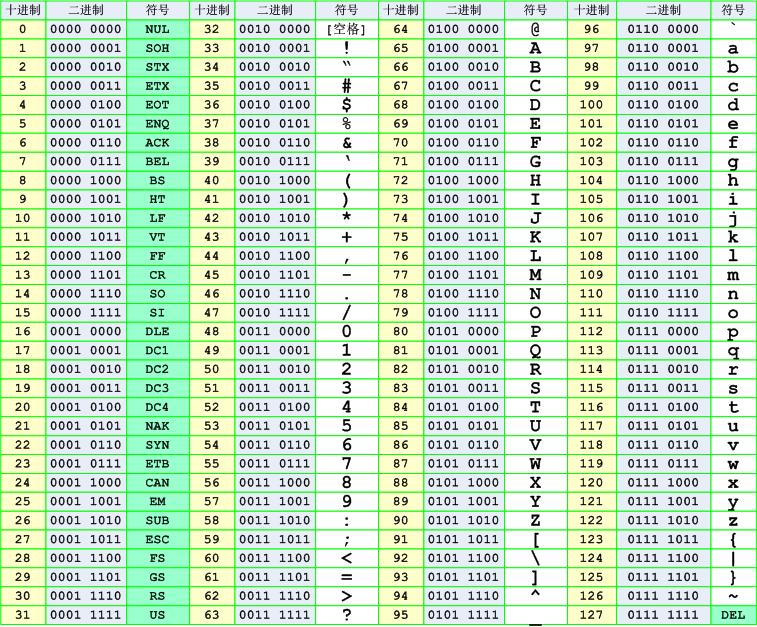
ASCII:
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,
Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
无论以什么编码,在内存中存储都 0 和1
ascii编码(美国):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
Shift_JIS编码(日本):
私 0b10001110 0b10000100
は 0b10000010 0b11001101
虽然国际语言是英语 ,但大家在自己的国家依然说自已的语言,不过出了国, 你就得会英语
编码也一样,虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
让美国人的电脑上都装上gbk编码
把你的软件编码以utf-8编码
第1种方法几乎不可能实现,第2种方法比较简单。 但是也只能是针对新开发的软件。那么怎么办呢?
unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,意思就是,你写的是gbk的“路飞学城”,但是unicode能自动知道它在unicode中的“路飞学城”的编码是什么,如果这样的话,那是不是意味着,无论你以什么编码存储的数据 ,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示啦。
上面的utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode。
二、Python的编码
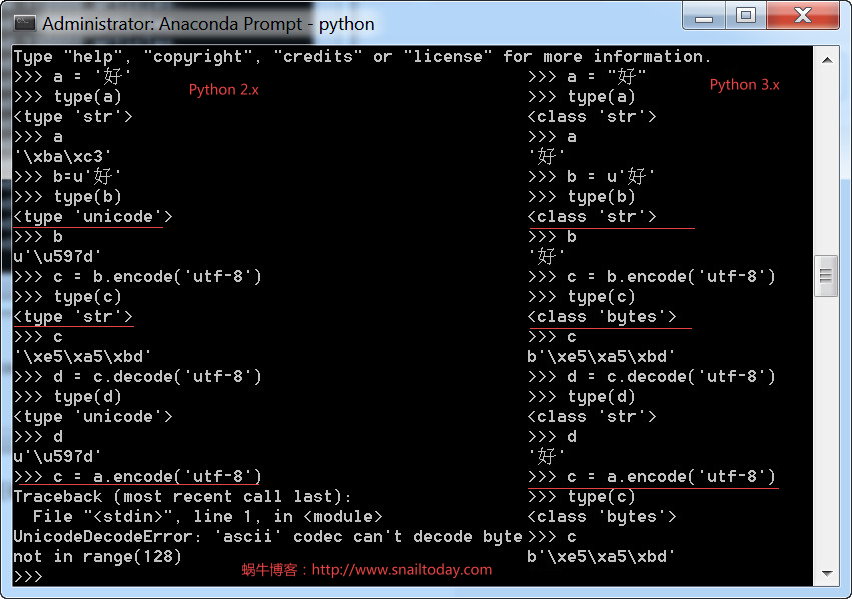
上面就是python2与python3的编码对比。
下面看个例子:
s = '路飞学城' print s
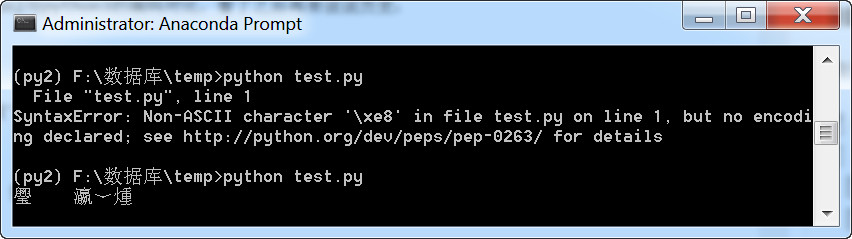
执行时会出错,
SyntaxError: Non-ASCII character '\xe6' in file test.py on line 4, but no encodi
ng declared; see http://python.org/dev/peps/pep-0263/ for details
如果加上“# -*- coding: utf-8 -*-”,则是乱码。
原因:
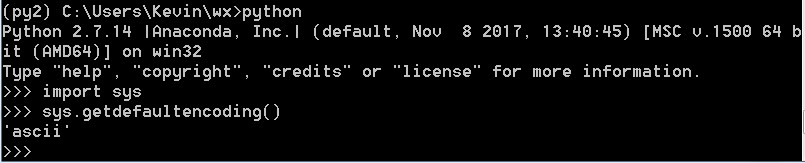
由于文件中含有中文,且py文件中没有指定编码方式,python会按照系统的默认编码解析执行print.py(这里的系统默认编码是ascii,查看系统的默认编码,可以调用sys.getdefaultencoing()函数),因此会提示Non-ASCII character的错误。
想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味着什么你知道么?。。。意味着,你以utf-8编码的文件,在windows是乱码。
乱是正常的,不乱才不正常,因为只有2种情况 ,你的windows上显示才不会乱
- 字符串以GBK格式显示
- 字符串是unicode编码
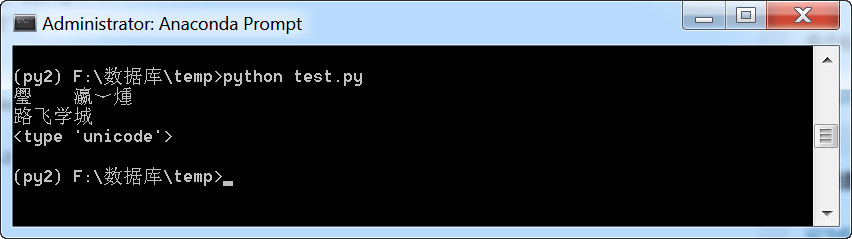
下面我们通过代码进行转码,将上面的代码改成:
# -*- coding: utf-8 -*-
s = '路飞学城'
print s
s2 = s.decode('utf-8')
print s2
print type(s2)
执行结果:
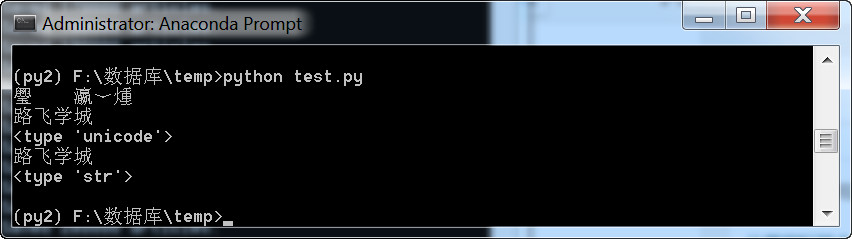
下面再来试试encode
# -*- coding: utf-8 -*-
s = '路飞学城'
print s
s2 = s.decode('utf-8')
print s2
print type(s2)
s3 = s2.encode('GBK')
print s3
print type(s3)
执行结果:
unicode字符是有专门的unicode类型来判断的,但是utf-8,gbk编码的字符都是str,你如果分辨出来的当前的字符串数据是何种编码的呢? 有人说可以通过字节长度判断,因为utf-8一个中文占3字节,gbk一个占2字节。
继续看代码:
# -*- coding: utf-8 -*-
s = '你好'
print type(s)
s2 = s.decode('utf-8')
s3 = s2.encode('GBK')
print type(s3)
print (s3,s)
执行结果:
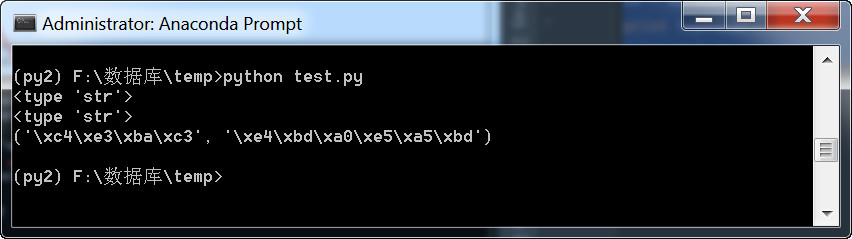
下面再来说说历史,在上图上中的“\xe4\xbd\xa0\xe5\xa5\xbd”这一串字符是什么呢?
是一个个的16进制表示的二进制字节,我们怎么称呼这样的数据呢?直接叫二进制么?也可以, 但相比于010101,这个数据串在表示形式上又把2进制转成了16进制来表示,这是为什么呢? 哈,为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。
说这个有什么意思呢?
想告诉你一个事实, 就是,python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事
除此之外呢, python2里还有个单独的类型是unicode , 把字符串解码后,就会变成unicode。

由于Python创始人在开发初期认知的局限性,其并未预料到python能发展成一个全球流行的语言,导致其开发初期并没有把支持全球各国语言当做重要的事情来做,所以就轻佻的把ASCII当做了默认编码。 当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2 就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型。
时间来到2008年,python发展已近20年,创始人龟叔越来越觉得python里的好多东西已发展的不像他的初衷那样,开始变得臃肿、不简洁、且有些设计让人摸不到头脑,比如unicode 与str类型,str 与bytes类型的关系,这给很多python程序员造成了困扰。
龟叔再也忍不了,像之前一样的修修补补已不能让Python变的更好,于是来了个大变革,Python3横空出世,不兼容python2,python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。

最后一个问题,为什么在py3里,把unicode编码后,字符串就变成了bytes格式? 你直接给我直接打印成gbk的字符展示不好么?我想其实py3的设计真是煞费苦心,就是想通过这样的方式明确的告诉你,想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
Python2.7
在Python2.x中str和unicode之间是如何转换的呢?

从下图可以看出,如果是str类型,用encode就会出错。
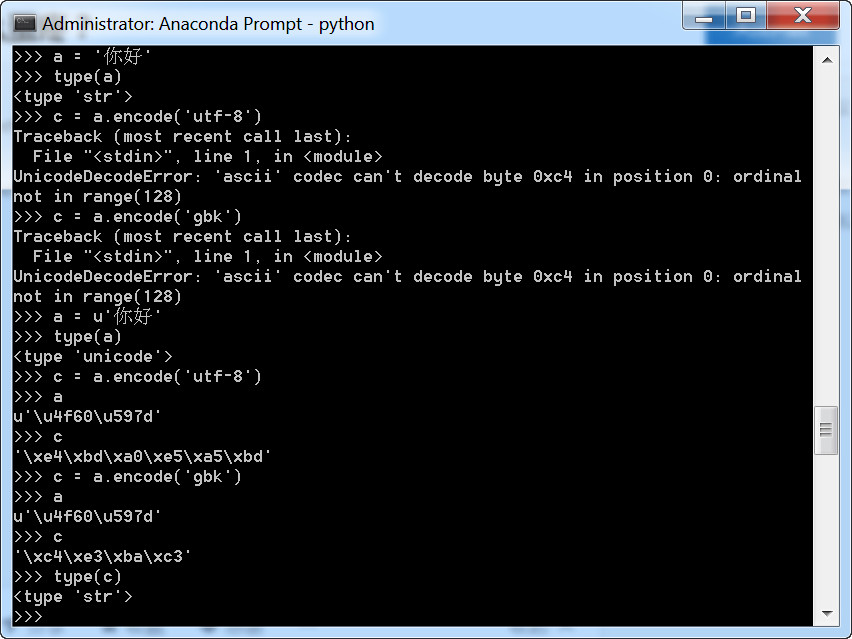
再看一下decode,encode的例子:
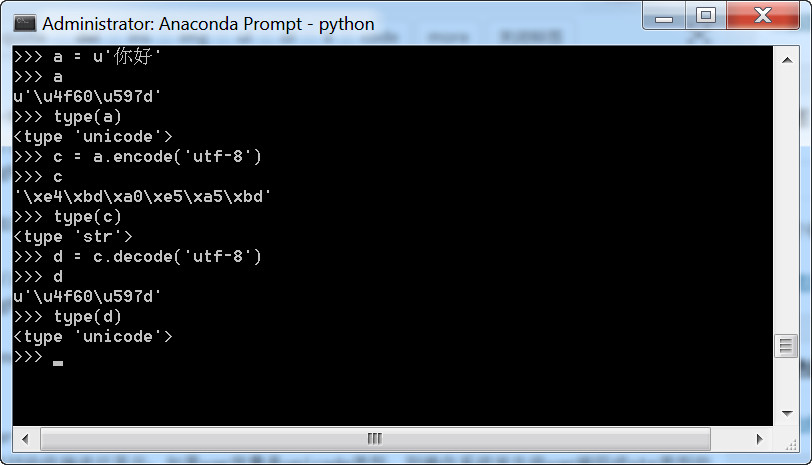
Python2.7中调用print打印var 变量时,操作系统会对var做一定的字符处理:如果var是str类型的变量,则直接将var变量交付给终端进行显示;如果var变量是unicode类型,则操作系统首先将var编码成str类型的对象(编码格式取决于stdout的编码格式),然后再交由终端进行显示。在终端显示时,如果str类型的变量的编码方式和终端设置的编码方式不一致,很可能会出现乱码问题。
编码出错一般是Non-ASCII character和UnicodeEncodeError两类。
如何查看文件的编码方式:
Linux下:可以vi print.py,然后在命令模式下,输入:set fileencoding,查看文件的编码方式
windows下:用记事本打开,然后文件--另存为 在对话框最下面的编码那一栏就有文件对应的编码。
对于如unicode形式的字符串(str类型),转换成真正的unicode需要使用:
s.decode('unicode-escape')
测试:
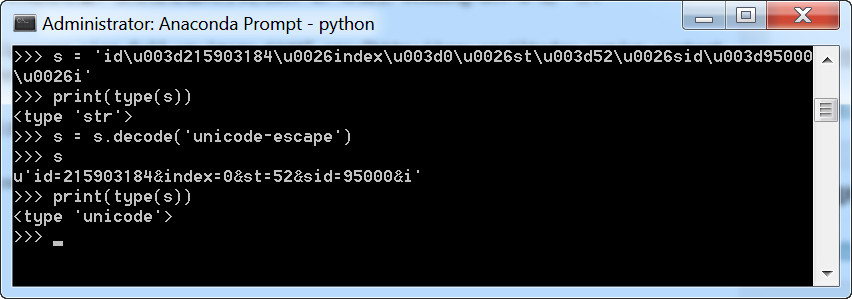
还有一种说法:如果在python文件中指定编码方式为utf-8(#coding=utf-8),那么所有带中文的字符串都会被认为是utf-8编码的byte string(例如:mystr="你好"),但是在函数中所产生的字符串则被认为是unicode string。问题就出在这边,unicode string 和byte string是不可以混合使用的,一旦混合使用了,就会产生如下 的错误
'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
例如:
self.response.out.write("你好"+self.request.get("argu"))
其中,"你好"被认为是byte string,而self.request.get("argu")的返回值被认为是unicode string。由于预设的解码器是ascii,所以就不能识别中文byte string。然后就报错了。解决方法:
1.将字符串全都转成byte string。
self.response.out.write("你好"+self.request.get("argu").encode("utf-8"))
2.将字符串全都转成unicode string。
self.response.out.write(u"你好"+self.request.get("argu"))
byte string转换成unicode string可以这样转unicode(unicodestring, "utf-8")
python3
在python3里,系统的默认编码已经变为了utf-8。
在python3.x中,可以直接输入汉字,不用加“# -*- coding: utf-8 -*-”了,也可以直接输出汉字。
比如下面的这样的代码可以直接执行了:
a = '测试' print(a)
字符就是unicode字符,字符串就是unicode字符数组,看下图可以证明
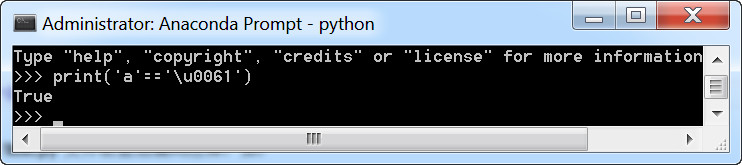
最后再提示一下,Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有:
Python解释器的默认编码
Python源文件文件编码
Terminal使用的编码
操作系统的语言设置
掌握了编码之前的关系后,挨个排错就好啦
http://www.cnblogs.com/alex3714/articles/7550940.html
另外还有一文:http://gitbook.cn/books/599d075614d1bc13375caeaf/index.html
十一、用python打印无法显示的字符