

Updated on Aug-11-2019
今天再试了一下,发现自己的chrome安装路径变成“C:\Users\Kevin\AppData\Local\Google\Chrome\Application”这个了。
然后将安装路径改成这个,又报如下错误:
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in positio
n 2-3: truncated \UXXXXXXXX escape
将代码改成下面这样就可以了:
driver = webdriver.Chrome(executable_path='C:\\Users\\Kevin\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe')
然后又报错,说chrome版本必须为70-73之间,我的已经是76了。
selenium.common.exceptions.SessionNotCreatedException: Message: session not crea
ted: Chrome version must be between 70 and 73
(Driver info: chromedriver=73.0.3683.68 (47787ec04b6e38e22703e856e101e840b65af
e72),platform=Windows NT 6.1.7601 SP1 x86_64)
所以又重新下载了chromedriver.exe进行替换,终于好了
--------------------------------------------------------------------------------------
今天试用了一下selenium。
一、首先通过pip命令安装,非常顺利。
二、然后执行py文件的时候,出现下面的错误提示:
Message: 'chromedriver.exe' executable needs to be in PATH. Please see https://s
ites.google.com/a/chromium.org/chromedriver/home
三、下载chromedriver
淘宝镜像:http://npm.taobao.org/mirrors/chromedriver/
注意 :下载的时候一定要注意版本,因为chromedriver的版本要与你使用的chrome版本对应才能使用。
| chromedriver版本 | 支持的Chrome版本 |
|---|---|
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
| v2.29 | v56-58 |
| v2.28 | v55-57 |
| v2.27 | v54-56 |
| v2.26 | v53-55 |
| v2.25 | v53-55 |
| v2.24 | v52-54 |
| v2.23 | v51-53 |
| v2.22 | v49-52 |
| v2.21 | v46-50 |
| v2.20 | v43-48 |
| v2.19 | v43-47 |
| v2.18 | v43-46 |
| v2.17 | v42-43 |
| v2.13 | v42-45 |
| v2.15 | v40-43 |
| v2.14 | v39-42 |
| v2.13 | v38-41 |
| v2.12 | v36-40 |
| v2.11 | v36-40 |
| v2.10 | v33-36 |
| v2.9 | v31-34 |
| v2.8 | v30-33 |
| v2.7 | v30-33 |
| v2.6 | v29-32 |
| v2.5 | v29-32 |
| v2.4 | v29-32 |
四、配置
将chromedriver.exe这个文件放到chrome的安装目录下,比如我的电脑就是:C:\Program Files (x86)\Google\Chrome\Application
然后右键单击我的电脑,在弹开的菜单中选中“属性功能,在弹出的菜单中选择”高级系统设置”->环境变量。
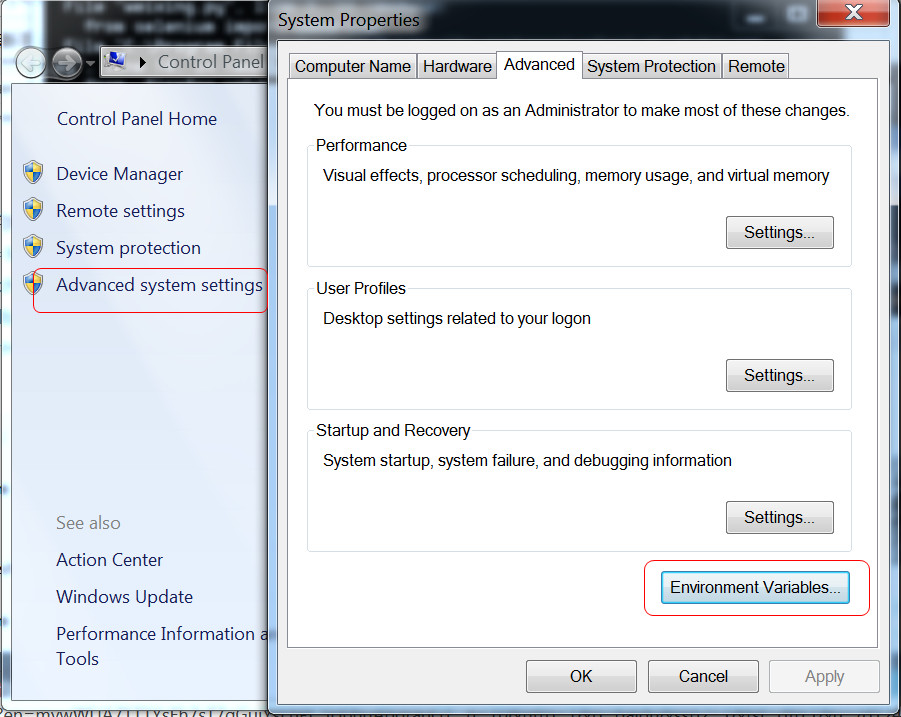 修改path,在最后面添加 ;C:\Program Files (x86)\Google\Chrome\Application
修改path,在最后面添加 ;C:\Program Files (x86)\Google\Chrome\Application
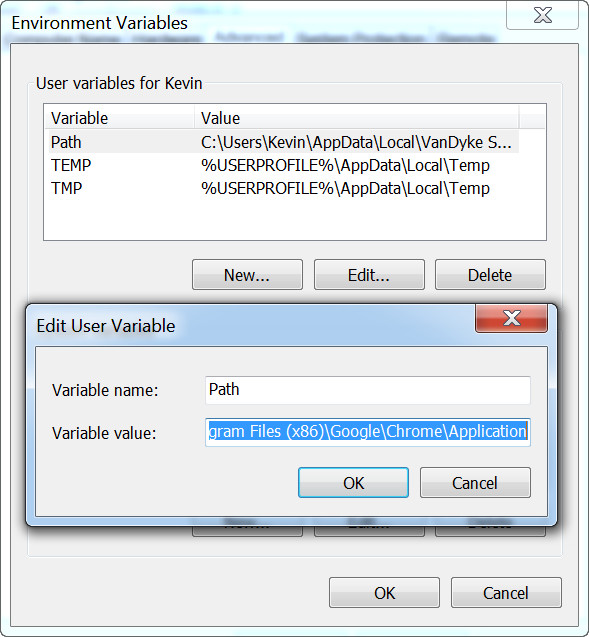
五、解决
我按上面的方法配置之后,还是显示:
Message: 'chromedriver.exe' executable needs to be in PATH. Please see https://s
ites.google.com/a/chromium.org/chromedriver/home
又尝试了将chromedriver.exe得到到python.exe所在目录,复制到anaconda下面的script目录,得到到要执行的py文件所在的目录都不行。
后来看到有人说,其实在环境变量设置完PATH重启就行了,或者在代码中写成:
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
就可以了,我一看,源代码直接写成了:
driver = webdriver.Chrome("C:\chromedriver.exe")
难怪出错了,改了这行代码之后,终于chrome运行正常了。
六、测试
我们在一个py文件中输入以下代码,并执行。
from selenium import webdriver
browser = webdriver.Chrome() #如果只有前面两行,则打开一个空白浏览器
browser.get("http://www.baidu.com")
print(browser.page_source)
browser.close()
就会打开baidu.com网站。
七、Mar.30.2019更新
今天想再一次使用selenium+chrome的时候,出现了问题,按上面的步骤操作,可是还是老是出现如下错误:
selenium.common.exceptions.WebDriverException: Message: 'chromedriver.exe' execu
table needs to be in PATH. Please see https://sites.google.com/a/chromium.org/ch
romedriver/home
解决方案:
将chromedriver.exe这个文件放到python的根目录下,比如,我用的是Anaconda,那么就放到:C:\ProgramData\Anaconda3 这下面。
然后再测试代码,终于成功了。
Updated on May-18-2020
其实不需要设置 sys path,只需要将chromedriver放到程序所在的文件夹下面就可以了。
五、开发快排笔记
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
其他代码(不知何原因,换ua,resolution测试不成功。
import random
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
# from bs4 import Beautifulsoup
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import TimeoutException
# url ="https://www.bejson.com/httputil/clientinfo/"
url = "http://www.gongjuji.net/browser/screen/"
def get_random_resolution():
resolution = random.choice([i.replace('\n','').split('*') for i in open('resolution.txt').readlines()])
return resolution
def get_random_ua():
a = [i.replace('\n','').strip() for i in open('ua.txt').readlines()]
ua = random.choice(a)
return ua
resolution = get_random_resolution()
ua = get_random_ua()
browser = webdriver.Chrome()
mobile_emulation = {
"deviceMetrics":{
"width":int(resolution[0]),
"height":int(resolution[1]),
"pixelRatio":3.0,
"touch":False
},
"userAgent":ua
}
chrome_options = Options()
#设置客户端分辨率与UA
chrome_options.add_experimental_option('mobileEmulation', mobile_emulation)
#取消“chrome正受到自动测试软件的控制”的提示
chrome_option.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(options=chrome_options)
#设置加载超时
browser.set_page_load_timeout(120)
#js的加载超时
browser.set_script_timeout(120)
#清空cookie
browser.delete_all_cookies()
browser.get(url)
七、webbrowser访问网页
import webbrowser
sites = random.choice(['baid.com','sohu.com','163.com'])
visit = "http://{}".format(sites)
webbrowser.open(visit)
参考:https://www.cnblogs.com/liugp/p/10563301.html
八、显式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
下面是一些条件判断:
title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert
九、异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。